
本章概述
- 创建CephFS
- 验证CephFS
- 创建普通用户
- 客户端准备工作
- 挂载ceph-fs
- ceph mds高可用
- 通过 ganesha 将 cephfs 导出为 NFS
前言
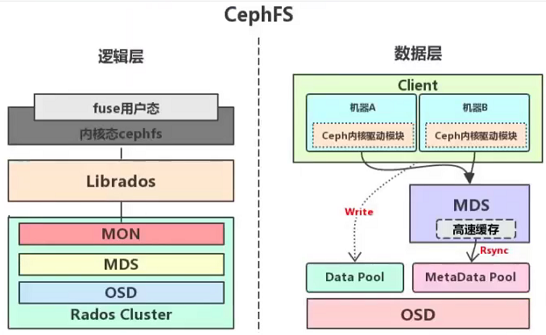
ceph FS 即 ceph filesystem,可以实现文件系统共享功能(符合POSIX标准),客户端通过 ceph 协议挂载并使用 ceph 集群作为数据存储服务器。
官网链接:https://docs.ceph.com/en/quincy/cephfs/
Ceph FS 需要运行 Meta Data Services(MDS)服务,其守护进程为 ceph-mds,ceph-mds进程管理在cephFS 上存储的文件相关的元数据,并协调对 ceph 存储集群的访问。
在linux系统使用ls等操作查看某个目录下文件的时候,会有保存在磁盘上的分区表记录文件的名称、创建日期、大小、inode(使用df -i命令可以查看)及存储位置等元数据信息,cephfs上的数据则是被打散为若干个离散的object进行分布式存储,并没有统一保存文件的元数据,而是将文件的元数据保存到一个单独的存储池metadata pool,但是客户端并不能直接访问metadata pool中的元数据信息,而是在读写数据的时候由MDS(metadata server)进行处理,读数据的时候由MDS从metadata pool加载元数据然后缓存在内存(用于后期快速响应其他客户端的请求)并返回给客户端,写数据的时候由MDS缓存在内存并同步到metadata pool。
注:ceph的元数据保存在bluestore中,具体查看2.6章节。块存储的元数据随着object一块存储,当客户端挂载存储时,可以直接读取数据的元数据。而cephFS存在两个存储池:数据存储池和元数据存储池,客户端不能挂载两个存储池,因此为了方便读取元数据,cephFS需要启用MDS服务
架构图如下:
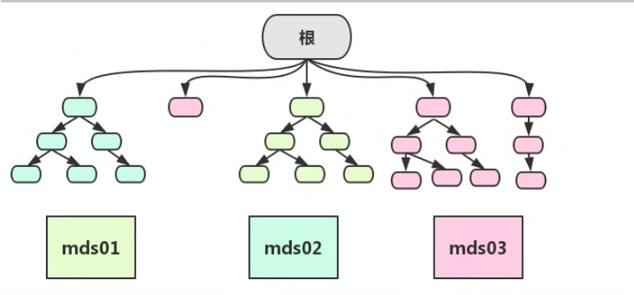
cephfs的mds数据结构类似于linux系统的根形目录结构及nginx中的缓存目录分层一样。
7.1 创建CephFS
CephFS创建、挂载以及MDS的创建步骤请参考4.3章节,这里不再重复
7.2 验证CephFS
查看cephfs服务状态,只有一个在线

查看指定的cephfs状态
cephadmin@ceph-deploy:~/ceph-cluster$ ceph fs status mycephfs

7.3 创建普通用户
创建账户(deploy节点执行)
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth add client.test02 mon 'allow r' mds 'allow rw' osd 'allow rwx pool=cephfs-data' #给普通用户授权,mon读权限,mds读写权限(需要想mds写入元数据),osd读写执行权限查看账号:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth get client.test02

创建用 keyring 文件,将test02用户信息导入keyring用于验证
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth get client.test02 -o ceph.client.test02.keyring

创建key文件,用于客户端挂载时验证使用
cephadmin@ceph-deploy:~/ceph-cluster$ ceph auth print-key client.test02 > test02.key
验证keyring文件

7.4 客户端准备工作
1、在客户端服务器(ceph-client2 172.31.7.152)安装以下安装包
[root@ceph-client2 ~]# yum install epel-release -y
[root@ceph-client2 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
[root@ceph-client2 ~]# yum install ceph-common -y2、同步客户端认证文件
在deploy节点执行命令
scp ceph.conf ceph.client.test02.keyring test02.key root@172.31.7.152:/etc/ceph/
3、在客户端进行验证
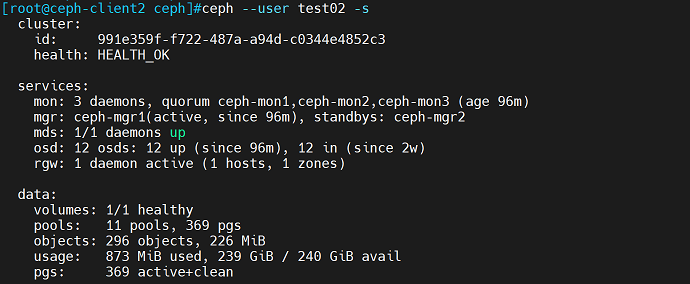
查看ceph集群信息:
[root@ceph-client2 ceph]# ceph --user test02 -s
7.5 挂载ceph-fs
客户端挂载有两种方式,一种是内核空间,一种是用户空间,内核空间挂载需要内核支持 ceph 模块,用户空间挂载需要安装 ceph-fuse
7.5.1 内核空间挂载ceph-fs
要求内核支持ceph模块
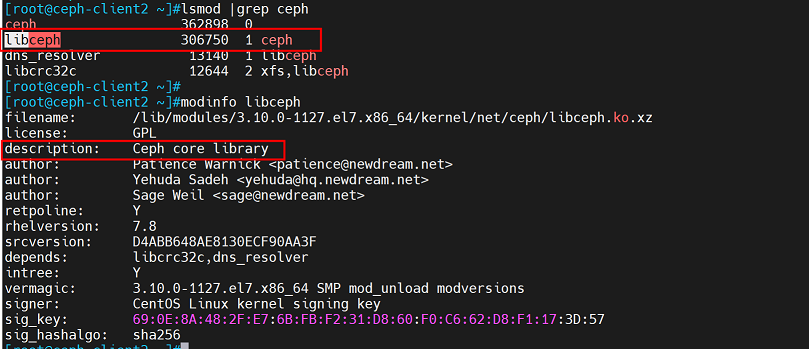
查看内核是否支持ceph
[root@ceph-client2 ~]#lsmod |grep ceph
[root@ceph-client2 ~]#modinfo libceph
7.5.1.1 客户端通过key文件挂载
注意:需要将key文件复制到客户端本地才可以通过这种方式挂载cephfs
在客户端服务器172.31.7.152上
1、创建挂载目录:
mkdir /data
2、挂载cephfs
[root@ceph-client2 ~]# mount -t ceph 172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789:/ /data -o name=test02,secretfile=/etc/ceph/test02.key
参数说明:
172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789:/ #是指mon的地址和端口,注意要加上根目录/
/data #是指挂载目录
-name #指定普通用户test02
secretfile #指定key文件路径,即/etc/ceph/test02.key 3、验证:
查看磁盘情况
df -Th

写入数据
[root@ceph-client2 ceph]#cp /var/log/messages /data
[root@ceph-client2 ceph]#ls /data

7.5.1.2 客户端通过key挂载
注意:如果客户端本地不方便存放key文件(如:在容器内),则可以通过key直接挂载,这里不需要将key文件复制到客户端本地。
1、查看key文件
[root@ceph-client2 ceph]#cat /etc/ceph/test02.key

2、卸载上一步骤的挂载 #如果是第一次挂载,可忽略该步骤
umount /data
3、通过key挂载cephfs
[root@ceph-client2 ~]# mount -t ceph 172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789:/ /data -o name=test02,secret=AQCFei9kClBWDxAAwYDZPGefTZjIWV7FytxKOw==
参数说明:
172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789:/ #是指mon的地址和端口,注意要加上根目录/
/data #是指挂载目录
-name #指定普通用户test02
secret #指定key,即/etc/ceph/test02.key中的key 4、验证
查看本地磁盘情况,挂载成功

7.5.1.3 设置开机自动挂载
1、配置/etc/fstab
vim /etc/fstab
172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789:/ /data ceph defaults,name=test02,secretfile=/etc/ceph/test02.key,_netdev 0 0
备注:在/etc/fstab文件配置挂载项时要添加_netdev参数(上面标红部分),表示该设备为网络设,当系统联网后再进行挂载操作,以免系统开机时间过长或开机失败2、重启设备进行验证 #重启操作只在实验环境进行,生产环境可忽略该步骤
reboot
3、查看挂载
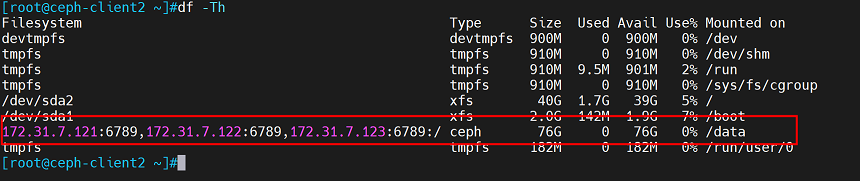
查看文件,message文件还在

7.5.2 用户空间挂载ceph-fs
如果内核本较低而没有 ceph 模块,那么可以安装 ceph-fuse 挂载,但是这种挂载方式磁盘读写性能较差,推荐使用内核模块挂载。
7.5.2.1 客户端准备工作
1、在客户端服务器安装ceph-fuse安装
[root@ceph-client2 ~]# yum install epel-release -y
[root@ceph-client2 ~]# yum install https://mirrors.aliyun.com/ceph/rpm-octopus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
[root@ceph-client2 ~]# yum install ceph-common -y
[root@ceph-client2 ~]# yum install ceph-fuse -y #安装ceph-fuse安装包2、同步客户端认证文件
在deploy节点执行命令
scp ceph.conf ceph.client.test02.keyring test02.key root@172.31.7.152:/etc/ceph/7.5.2.2 ceph-fuse挂载
1、通过 ceph-fuse 挂载 ceph
[root@ceph-client2 ~]# mkdir /data
[root@ceph-client2 ~]# ceph-fuse --name client.test02 -m 172.31.7.121:6789,172.31.7.122:6789,172.31.7.123:6789 /data
2、验证

7.5.2.3 配置开机自启动
1、配置/etc/fstab
[root@ceph-client2 ~]# vim /etc/fstab #由于指定了ceph.conf配置文件的路径,mon的ip地址可以从配置文件获取,因此这里可以不写mon的地址,直接写为none即可
none /data fuse.ceph ceph.id=test02,ceph.conf=/etc/ceph/ceph.conf,\_netdev,defaults 0 02、重启服务器并验证
reboot
重启后查看磁盘挂载情况
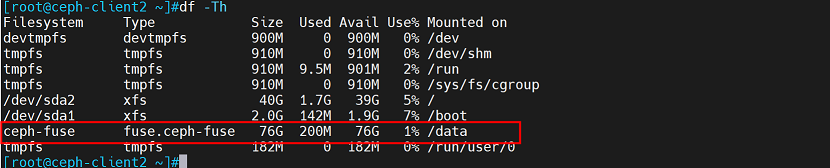
7.6 ceph mds高可用
ceph mds(metadata server)作为ceph的访问入口,需要实现高性能即数据备份功能,二MDS支持多MDS结构,甚至还能实现类似于redis cluster的多主从结构,以实现MDS服务的高性能和高可用。假设启动4个MDS进程,设置最大max_mds为2,这时候有2个MDS成为主节点,另外的2个MDS作为备份节点。
参考链接:https://docs.ceph.com/en/latest/cephfs/add-remove-mds/
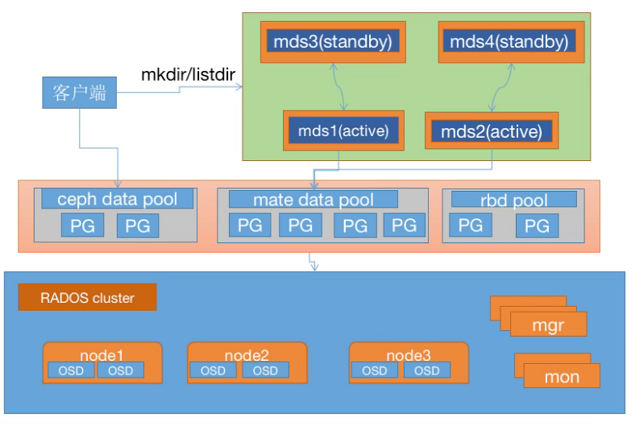
架构逻辑说明:
默认情况下,mds主备节点没有绑定关系,当主节点宕机后,备节点从metadata pool加载元数据,然后接管主节点。
上图显示的MDS结构中,mds1绑定mds3,mds1为主,对应mds为备;mds2绑定mds4,mds2为主,对应mds4为备;备节点会实时从主节点同步元数据,当主节点宕机后,备节点会立即接管,这样一来会大大缩短数据恢复时间,将业务影响降到最低。
但这样配置存在资源浪费,即两个备节点服务器的资源平时不会被使用,只有主节点故障时才会使用(MDS故障率很低)。为了使资源充分利用,可以直接配置mds为4个主节点,但是如果某个主节点故障,会导致mds节点的变化迁移,需将主节点修复后重新同步元数据。
架构图:
设置每个主节点的备份 MDS,也就是如果此主节点当前的 MDS 出现问题马上切换到另个MDS。设置备份的方法有很多,常用选项如下:(以下配置如果要添加,需要在mds节点进行添加)
mds_standby_replay:值为 true 或 false,true 表示开启 replay 模式,这种模式下主 MDS内的数据将实时与从 MDS 同步,如果主节点宕机,从节点可以快速的切换。如果为 false 只有宕机的时候才去同步数据,这样会有一段时间的中断。
mds_standby_for_name:设置当前 MDS 进程只用于备份指定名称的 MDS(即指定该节点的主节点是谁),配置时指定主的进程名(即主节点服务器的主机名)。
mds_standby_for_rank:设置当前 MDS 进程只用于备份于哪个 Rank(上级节点),通常为 Rank 编号。另外在存在多个 CephFS 文件系统中,还可以使用 mds_standby_for_fscid 参数来为指定不同的文件系统。
mds_standby_for_fscid:指定 CephFS 文件系统 ID,需要联合 mds_standby_for_rank 生效,如果设置 mds_standby_for_rank,那么就是用于指定文件系统的指定 Rank,如果没有设置,就是指定文件系统的所有 Rank。7.6.1 环境准备
在4.3.1章节演示时,已经在mgr1上安装了mds服务
而mds需要两主两备,因此还需要在3个节点上安装mds服务。分别在mg2(172.31.7.125)、mon2(172.31.7.122)、mon(172.31.7.123)3节点安装mds服务
7.6.2 添加mds服务器
将 ceph-mgr2 和 ceph-mon2 和 ceph-mon3 作为 mds 服务角色添加至 ceph 集群,最后实两主两备的 mds 高可用和高性能结构。
1、三台主机分别安装ceph-mds 服务
root@ceph-mgr2:~# apt install ceph-mds
root@ceph-mon2:~# apt install ceph-mds
root@ceph-mon3:~# apt install ceph-mds
2、在deploy节点添加mds服务器
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mgr2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mon2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy mds create ceph-mon3
注意:添加节点时,如果deploy节点上的配置文件存在更新,是最新的配置,mon节点上的配置不是最新的,会添加不成功,可以使用--overwrite-conf配置进行覆盖。
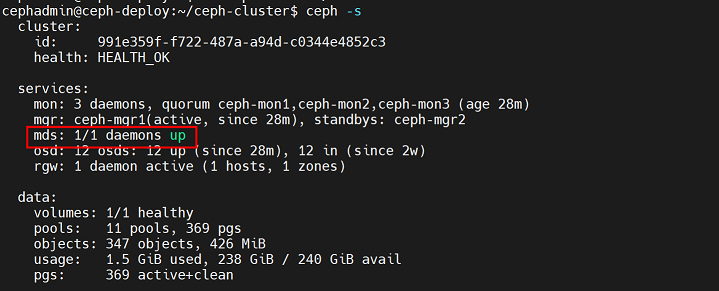
3、验证 mds 服务器当前状态:
cephadmin@ceph-deploy:~/ceph-cluster$ ceph mds stat

4、验证 ceph 集群当前 状态(当前ceph集群mds为一主三从)
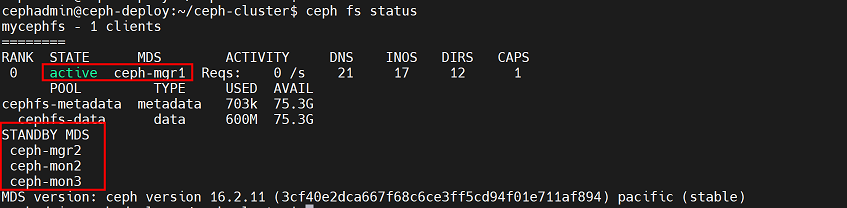
7.6.3 获取当前文件系统状态
可以获取mds配置,即max_mds参数,值为1,说明只有一个主
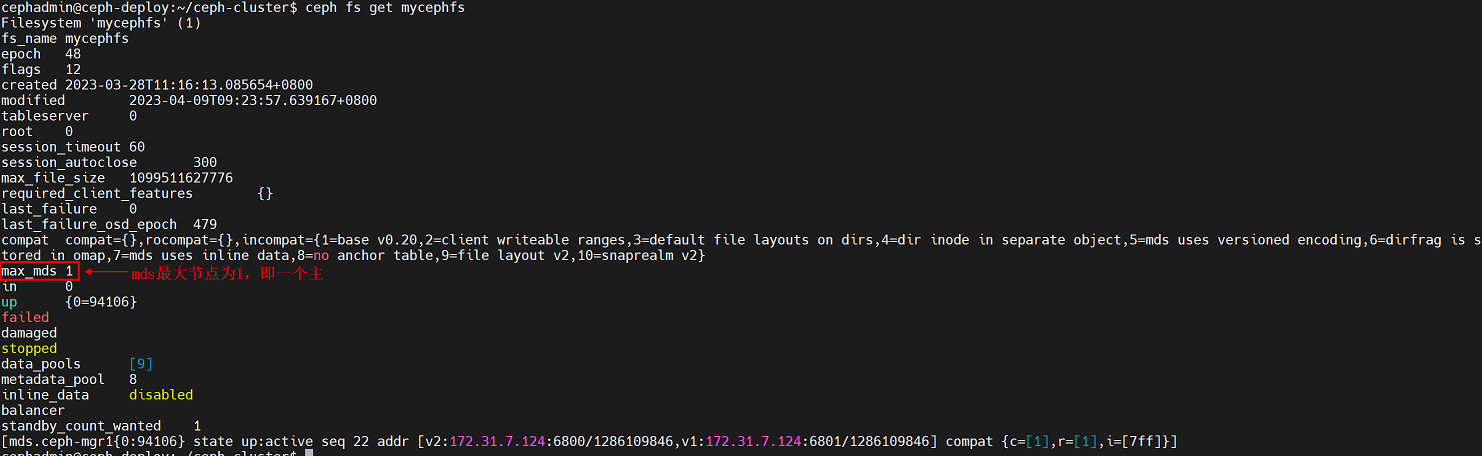
7.6.4 设置处于激活状态 mds 的数量
目前有四个 mds 服务器,但是有一个主三个备,可以优化一下部署架构,设置为为两主两备。
cephadmin@ceph-deploy:~/ceph-cluster$ ceph fs set mycephfs max_mds 2
查看mds状态,有两主两备
主节点为:ceph-mgr1、ceph-mon3
备节点为:ceph-mg2、ceph-mon2
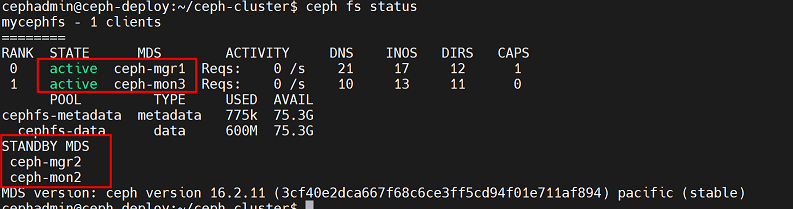
注意:此时虽然有两主两备,但是主备之间并未绑定,因此备节点还不会从主节点实时同步元数据
7.6.5 MDS 高可用优化(MDS主备绑定)
目前的状态是 ceph-mgr1 和 ceph-mon3 分别是 active 状态,ceph-mon2 和 ceph-mgr2分别处于 standby 状态,现在可以将 ceph-mgr2 设置为 ceph-mgr1 的 standby,将ceph-mon2 设置为 ceph-mon3 的 standby,以实现每个主都有一个固定备份角色的结构(主备绑定的场景只适用于两主两备的情况)

则修改配置文件如下:
cephadmin@ceph-deploy:~/ceph-cluster$ vim ceph.conf #标红部分内容为新增配置
[global]
fsid = 991e359f-f722-487a-a94d-c0344e4852c3
public_network = 172.31.7.0/24
cluster_network = 192.168.7.0/24
mon_initial_members = ceph-mon1
mon_host = 172.31.7.121
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon clock drift allowed = 2
mon clock drift warn backoff = 30
[mds.ceph-mgr1]
mds_standby_for_name = ceph-mgr2 #指定mgr1的主为mgr2,当mgr2作为主节点是,其备节点为mgr1
mds_standby_replay = true #开启实时同步
[mds.ceph-mon3]
mds_standby_for_name = ceph-mon2 #指定mon3的主为mon2,当mon3作为主节点是,其备节点为mon2
mds_standby_replay = true
[mds.ceph-mgr2]
mds_standby_for_name = ceph-mgr1 #指定mgr2的主为mgr1,当mgr1作为主节点是,其备节点为mgr2
mds_standby_replay = true
[mds.ceph-mon2]
mds_standby_for_name = ceph-mon3 #指定mon2的主为mon3,当mon2作为主节点是,其备节点为mon3
mds_standby_replay = true注意:
为了防止服务重启或者服务器重启导致主备节点角色(主备角色)发生变化导致服务不可用,在配置文件中将绑定的两个主备节点指定互为主备,这样一来无论两个节点角色如何变化,配置文件都可用。
目前情况下,mgr1和mon3为主,在配置文件中指定其备节点分别是mgr2和mon2。除此之外,还指定了当mgr1和mon3为备节点时,它的主为mgr2和mon2,这样一来,主备节点绑定以后,无论两个节点的主备角色如何切换,都不会影响mds服务。(这样配置的原因是:mds服务重启以后,绑定的两个节点主备角色可能会发生变化)
7.6.6 分发配置文件并重启 mds 服务
1、在deploy节点分发配置文件保证各 mds 服务重启有效
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mon3
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mon2
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mgr1
cephadmin@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-mgr2
2、在mds四个节点分别重启mds服务,使配置文件生效
[root@ceph-mon2 ~]# systemctl restart ceph-mds@ceph-mon2.service
[root@ceph-mon3 ~]# systemctl restart ceph-mds@ceph-mon3.service
[root@ceph-mgr2 ~]# systemctl restart ceph-mds@ceph-mgr2.service
[root@ceph-mgr1 ~]# systemctl restart ceph-mds@ceph-mgr1.service
7.6.7 验证集群高可用状态
注意:新版本ceph,主节点mds服务故障后,可能会出现非绑定关闭的节点去接管主的情况
1、查看mds服务主备关系
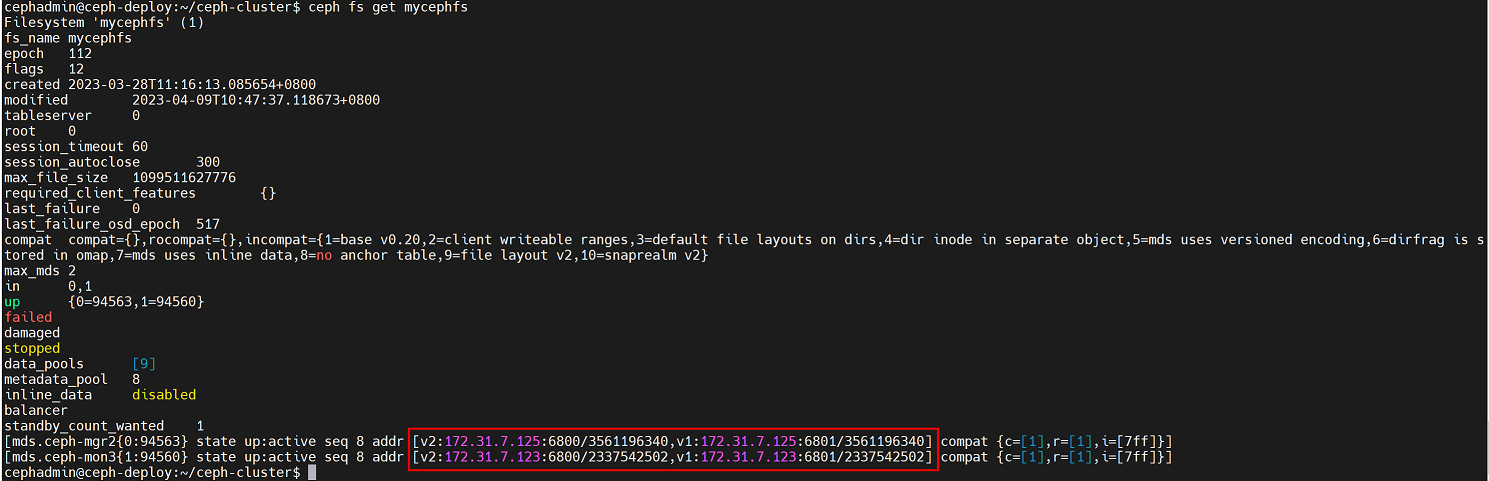
cephadmin@ceph-deploy:~/ceph-cluster$ ceph fs status
可以看到mg1和mgr2的主备角色发生了变化,即mgr2为主,mgr1为备,但配置文件中两个节点互为绑定,即便主备角色发生变化,也不影响mds服务
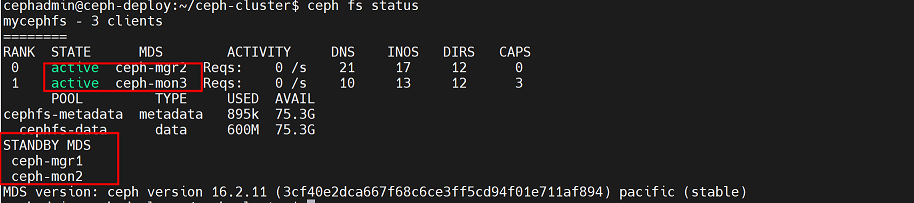
2、查看 active 和 standby 对应关系:
7.7 通过 ganesha 将 cephfs 导出为 NFS
使用场景:老的集群使用的是nfs协议,修改集群配置比较麻烦,将cephfs转换为nfs,但这种方式只适合读写量较小的场景,其读写性能比ceph的读写性能差很多,因此推荐直接挂载cephfs
通过 ganesha 将 cephfs 通过 NFS 协议共享使用。
https://www.server-world.info/en/note?os=Ubuntu_20.04&p=ceph15&f=8
架构图:
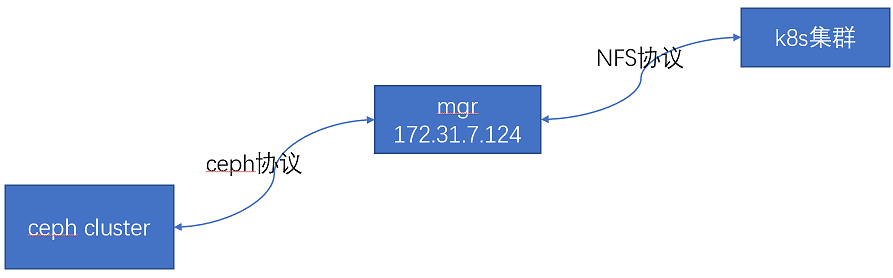
假设在mgr1节点172.31.7.124上进行配置,需要在mgr节点准备ceph.conf、用户的认证文件(要求用户对存储池有读写权限,这里以admin用户为例)
7.7.1 服务端配置
在 mgr 1节点172.31.7.124配置,需要提前在mgr1上准备好 ceph.conf 和 ceph.client.admin.keyring 认证文件。
1、在deploy节点把ceph.conf、admin用户的认证文件传给mgr节点
cephadmin@ceph-deploy:~/ceph-cluster$ scp ceph.conf ceph.client.admin.keyring root@172.31.7.124:/etc/ceph/
2、在mgr1节点172.31.7.124上安装nfs-ganesha-ceph包
root@ceph-mgr1:~# apt install nfs-ganesha-ceph
3、修改ganesha的配置文件(将配置文件中原有内容删除,直接把以下内容粘贴进去即可)
vim /etc/ganesha/ganesha.conf
# create new
NFS_CORE_PARAM {
# disable NLM
Enable_NLM = false;
# disable RQUOTA (not suported on CephFS)
Enable_RQUOTA = false;
# NFS protocol(NFS协议版本)
Protocols = 4; #如果想用NFS3协议版本,可改为3
}
EXPORT_DEFAULTS {
# default access mode(默认访问模式)
Access_Type = RW; #设置为读写权限,客户端具有读写权限
}
EXPORT {
# uniq ID(导出时的id,可自定义,如果有多个,不能重复)
Export_Id = 1;
# mount path of CephFS(cephfs导出的路径)
Path = "/"; #设置为ceph的根目录
FSAL {
name = CEPH;
# hostname or IP address of this Node(当前节点的主机名或ip地址)
hostname="172.31.6.104";
}
# setting for root Squash(设置权限)
Squash="No_root_squash"; #,No_root_squash是指不做权限映射,哪个用户写的文件属主就是谁
# NFSv4 Pseudo path(导出以后的挂载点)
Pseudo="/magedu"; #把cephfs根目录导出为NFS的/magedu目录
# allowed security options
SecType = "sys";
}
LOG {
# default log level
Default_Log_Level = WARN;
}4、重启ganesha服务并设置为开机自启动
root@ceph-mgr1:~# systemctl restart nfs-ganesha
root@ceph-mgr1:~# systemctl enable nfs-ganesha
5、查看ganesha服务是否正常启动
(1)查看服务状态
root@ceph-mgr1:~# systemctl status nfs-ganesha

(2)查看ganesha日志
tail -f /var/log/ganesha/ganesha.log #没有报错,说明启动正常

7.7.2 客户端挂载测试
在客户端服务器172.31.7.155上进行挂载(该节点为ubuntu系统)
1、安装nfs-common包(如果不安装,可能会不识别nfs)
root@ubuntu:~# apt install nfs-common
2、进行挂载
mkdir /data
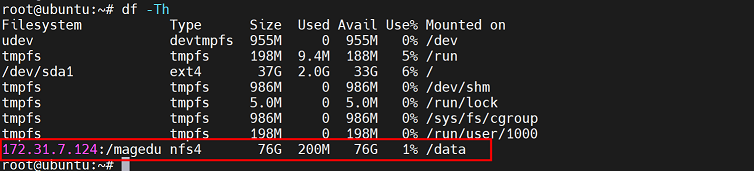
mount -t nfs 172.31.7.124:/magedu /data #这里的/magedu是指配置文件中指定的nfs挂载路径
3、查看磁盘情况

文章评论