
本章概要
- 数据收集的需求
- 数据处理必须的要素
- ELK相关组件介绍
- ELK架构介绍
- ELK详细配置
1、数据处理带来的需求
无论是哪一种数据库都需要对数据进行数据存储和数据检索两方面内容。
以MySQL为例,在数据检索方面:使用索引方式加速读操作。
mysql中的索引包括:B+Tree索引、HASH索引
在数据存储方面,mysql的存储引擎包括:
MyISAM存储引擎
MySQL5.1版本之前默认的存储引擎,MySQL5.5版本之后默认为InnoDB
支持全文索引(Fulltext),效率低
InnoDB存储引擎
B+Tree,即最左前缀索引,不支持全文索引
- 对于搜索引擎来说,面临两类问题:数据存储、数据处理
- google发表论文
海量数据存储的文件系统:GFS
分布式应用程序处理框架:MapReduce - 应运而生的开源领域产品:Hadoop
数据存储文件系统:HDFS
分布式应用程序处理框架:MapReduce
缺点:这两种系统能够遍历的实现数据的分布式存储和处理,但无法实现实现高效检索、根据关键词进行检索
这是因为互联网通用搜索引擎一般是根据一种独特的存储逻辑构建索引,支持用户对任何一个关键词进行独特搜索的存储系统,这种索引称之为倒排索引,有其独特的结构
2、数据处理必须的三要素
搜索引擎
- 数据检索需求:
1、面向客户端一侧的站内搜索引擎
2、站点或信息系统后台也需要一种内部的数据存储和检索分析系统,如日志 - 开源领域知名搜索引擎:
Lucene
是java语言开发的搜索引擎的类库
帮用户将待搜索的内容构建成可被搜索的格式--倒排索引
如果想使用Lucehe作为搜索引擎,必须在其之上再次开发出一个外壳
Sphinx
C++语言开发 - 基于Lucehe开发搜索引擎服务器程序:Solr,是一个搜索引擎服务器。但是,有了搜索引擎还需要有数据源进行检索。
名词解析:
倒排索引
对关键字进行切词,找到符合要求的文档,进行交集,找出最符合用户要求的文档返回给用户
如果进行交集以后出现多个符合关键字的结果,则需要对搜索的结果进行排序
结果的排序需要评估搜索结构对用户的价值有多高
评估方式:使用竞价方式、使用页面排序算法进行评估
页面排序算法:TF和IDF算法
基于词找文档数据分析处理
- 数据的获取需要ETL(抽取、转换、导入)工具
- 获取数据过程:
1、把数据从数据源抽取出来
2、可能还需要进行格式转换
3、导入到自己搜索引擎专用的存储系统中
拿到数据后对每一个独特的数据项做特定的分析操作 - 数据分析操作过程:
1、把整行文件信息做切词操作
把拿到的原始内容切割为用户常用的关键词,以便用户在基于词或短语搜索时,能匹配到用户所给定的词
2、格式转换
正规化:同义词替换,把对应的同义词,统统替换成一个单独的字符;转换字符大小写,转换为统一格式,如把大写全换为小写
数据存储
- 数据存储:
数据切词以后,进行存储数据时,要对数据增加属性进行标识,表明数据用途
3、ELK相关组件介绍
3.1 Elasticsearch介绍
Elasticsearch的由来
- Lucene搜索引擎数据存储:
三个重要术语:文档(Document)、类型(Type)、索引(Index)
Lucehe的数据存储,以json格式进行存储
json格式的数据,每一个独立段称之为文档Document
同一类型的多个文档组合起来叫做类型type
多个类型中的所有数据组合在一起形成一个数据库,这个库我们称之为索引
为了便于检索,把每一个数据项存储为独立的文档,每一个文档对应现实中一个独立数据项,如一个网页就是一个文档,一个word文档也是一个文档,mysql数据表中的一行数据也是一个文档 - Lucene和关系型数据库的对应关系
| Lucene | 关系型数据库 |
|---|---|
| Document | Row |
| Type | Table |
| Index | Database |
因此在搜索引擎上,所有的搜索过程在Index上实现
- Lucene只是JAVA开发的一个类库
无法实现以下功能:
只能检索和抽取数据,却无法存储这些数据
无法与用户交互,无法实现检索数据并返回结果 - 因此,需要给Lucehe开发一个外壳,外壳要有以下功能:
负责与客户端进行交互,如可以通过套接字接收用户请求,并把请求转为Lucehe某一特定的库所能完成的功能,并借助于Luncene转换为文档格式存储在文件系统之上
然后,该外壳的套接字还能接收用户请求,当用户发来一个关键词进行检索时,这个外壳能够把它转为一个特定的查询操作,替换为Luncene内部的可执行格式,并接收Lucehe的相应结果,然后返回客户端,并用用户比较容易接受的格式展示给用户
而这个外壳就是搜索引擎服务器程序Solr - Solr是早期的产品,单机运行,仅用于站内搜索。随着现在服务器日志量的增加,单机上的存储和检索已经超出单机所能承载的存储和计算能力,但Solr不支持多机运行
- 根据该需求开发出新的产品/外壳:以Lucehe为核心,开发的外壳让Lucehe扩展为能够在多机之上分布式协同以集群的方式运行
- 这个产品/外壳就是Elasticsearch,允许多机协同分布式运行
Elasticsearch介绍
- Elasticsearch运行模式:
不会事先把一个数据集直接接收过来当一个独立的数据项进行对待,而是把一个数据集接收过来以后事先划分成分片的形式进行 - 数据的分布式有两种:
1、以节点数量取模进行分布
该分布方式比较固化,以后节点数量的增减很不方便
2、不再基于节点数值取模,而是基于某个固定值进行取模 - Elasticsearch
是一种高效的存储数据、分析数据、检索日志
对数据进行分片存储
分片数可以由用户指定,如果不指定,默认为5片
节点数要大于等于分片数 - 对数据做冗余:
基于节点冗余
要对每个节点做主从,冗余方式比较固化
基于分片冗余
推荐使用分片冗余(即主分片、副本分片方式),冗余方式灵活多变
注意:
主分片和副本分片不能在同一节点上,副本分片的数量代表可以同时坏掉的节点数量;副本数量越多,节点容错能力越强,相对的磁盘空间利用率越低,一般情况下,一主两副比较常见,每一个分片在每一个节点上都被当做一个索引。 - 每一个分片在每一个节点上都被当做独立的索引来对待,假设每一个分片有一个副本。
如果集群中每一个节点都存在,那就说明所有分片的主副本都存在,这种状态称之为绿色健康状态
如果集群中某一个节点发生故障,那么其他节点的分片,要么缺少主分片,要么缺少副本分片,这种状态叫做黄色缺失状态
如果集群中两个节点发生故障,那么有可能某一分片的主副都会缺失,这就造成数据的丢失,种状态叫做红色状态 - 数据收集
如果是自己的网站,使用爬虫获取数据转为文档格式,导入Elasticsearch
如果是mysql数据库,从数据库获取数据转为文档格式,导入Elasticsearch
那么,如何把日志文件导入Elasticsearch呢?这就需要日志收集工具--Logstash。
3.2 Logstash介绍
Logstash
- Logstash 日志抓取工具
工作于生成日志的服务器节点之上,监控日志文件中追加进来的新日志信息,每追加进来一行日志,Logstash能够把该行抽取出来转为文档格式再发送给Elasticsearch
缺点:
重量级,文件占用空间很大
基于jruby研发,占用大量内存(jruby,使用java语言开发的ruby虚拟机)
Filebeat
-
再次开发版工具:beats (使用c语言+go语言研发)
-
beats分为以下几种:
Filebeat 从文件中搜集日志
Packetbeat 从网络中抓包获取信息
Eventbeat 从windows日志事件查看器中收集 -
搜集日志使用Filebeat即可
-
日志抽取出来后,进行存储和检索
-
Elasticsearch提供的是RESTful风格的API接口,用户可以通过web浏览器向Elasticsearch发送请求,包括发出检索请求,Elasticsearch通过http或https向客户端响应结果,但大多数用户没有能力直接调用http接口,因此需要一种应用程序用于向用户展示结果,该应用程序叫做Kibana
3.3 Kibana
- Kibana
支持以Elasticsearch为数据源的数据展示接口,提供一个前端页面,在该页面搜索文本框输入关键词可以帮我们搜索出对应索引中的内容,更重要的是,还可以把结果做聚合展示,支持折线图、柱状图、点状图、雷达图,做单维、多维的分析等
4、ELK架构介绍
ELK架构
- ELK,即Elasticsearch,Logstash,Kibana的组合
Logstash是一种数据抽取、转换和装入工具,即ETL工具,它把数据从数据源抽取出来,转换为文档格式,并再加载到Elasticsearch中
Elasticsearch是一种搜索引擎,能够把Logstash发送过来的数据在本地完成切词正规化、分析、存储并支持检索
Kibana提供给用户一个利用Elasticsearch的接口,完成数据检索、展示的非常直观的用户界面,是一个可视化工具
Elastic工具栈
-
由于Logstash太过重量级,因此加入了Filebeat,这四种工具总称为Elastic stack,即Elastic工具栈
-
但Logstash在其他维度还有其优势,Logstash文档化能力比Filebeat要强很多,因此在Elastic工具栈中仍然需要Logstash。
-
下面以tomcat为例,对ELK架构进行详细说明:
我们在tomcat服务器节点上部署Filebeat,负责收集tomcat日志信息,Elasticsearch不具备把数据进行文档化的能力,而Filebeat的文档化能力非常有限,但这是Logstash的长处,因此通常情况下会单独部署一台Logstash服务器。
当Filebeat收集日志以后,发送给Logstash Server,Logsta Server接收到Filebeat发送过来的日志后,在本地进行格式转换,即文档化,然后统一加载到Elasticsearch中。
注意:Filebeat只能做到ETL工具中的"E"(数据抽取)和"L"(加载),其中的"T"(格式转换)仍然需要Logstash来做。
Kibana通过http协议连接值Elasticsearch节点,与其通信,提供一个web界面与用户进行交互
但Kibana只能连接到一个Elasticsearch节点上,客户端访问也只能连接到一个节点上,这会极大的妨碍对Elasticsearch的使用,因此在Elasticsearch前端还应该增加一个负载均衡器,把客户端请求调度到多个Elasticsearch节点之上
这样一来,前端负载均衡器就成为了单点,需要做高可用,如果Kibana压力不大,不需要做调度,还可以直接在Elasticsearch节点上做keepalived集群,当其中一个节点出现故障时实现地址转移
Kibana一般部署在内网,如果想要在互联网访问Kibana客户端,需要在前端调度器上使用url进行反向代理开放出去,除此之外,为了安全起见,还需要做访问控制和认证 -
如果tomcat生成日志量不多的情况下,以上架构没有问题,如果tomcat生成日志量很大的情况下,Logstash服务器很有可能无法承载。
-
解决方案:
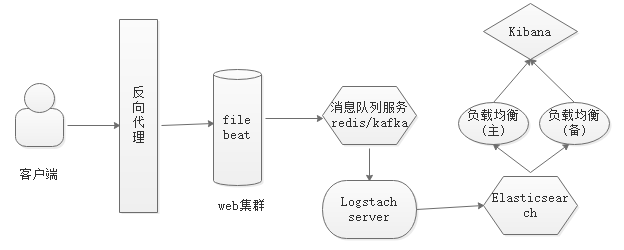
如果对日志访问不需要实时访问,以异步的方式进行协作,可以在Logstash前端加一个消息队列服务,所有的信息缓存在队列当中,然后Logstash server从消息队列中读取信息进行处理。这里要求消息队列能够承载所有信息的存储,可以使用redis充当消息队列服务器。
但是如果消息队列服务器存储的速度大于Logstash处理的速度,即进的速度大于出的速度,那么可能造成消息队列服务器的信息溢出
解决方法:提高Logstash的处理速度,增加Logstash server数量以增加处理消息队列服务器信息的速度
再大规模的架构中使用另外一种消息队列服务器:基于java开发的分布式消息队列服务器Kafka -
整体架构图如下所示:
5、ELK配置介绍
- ELK配置注意事项:
基于java研发,需要运行在jvm之上
需要先配置jvm,并对堆内存进行设置
创建集群,推荐使用奇数个节点,用于出现网络分区时,便于选举出代替主节点的网络分区
每个节点默认内存2G,每一个节点要确保时间同步
如果想要各节点之间能够通过主机名称访问,要确保主机名称正确,通过/etc/hosts文件进行主机名解析,不推荐使用dns解析,因为一旦dns服务器出现故障,那么集群也会出现问题
5.1 Elasticsearch配置
安装Elasticsearch,需要到官方站点下载
官网:www.elastic.co
当前主流为5.5版本
下载地址:https://www.elastic.co/downloads/past-releases
相关配置如下:
实验环境:
主机1:192.168.32.151 主机名:node01.magedu.com
主机2:192.168.32.152 主机名:node02.magedu.com
主机3:192.168.32.153 主机名:node03.magedu.com
主机4:192.168.32.154 主机名:master.magedu.com
客户端主机:192.168.32.128
cat /etc/hosts
[root@node01 elasticsearch]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.32.151 node01.magedu.com node01
192.168.32.152 node02.magedu.com node02
192.168.32.153 node03.magedu.com node03
192.168.32.154 master.magedu.com master
从官网下载elasticsearch-5.5.1.rpm软件包
Elasticsearch安装:
由于Elasticsearch是基于java开发的,需要安装java环境
在三台主机上分别安装java开发包
yum -y install java-1.8.0-openjdk-devel #安装java开发包,java版本最低是1.8.0
在三台主机上分别安装elasticsearch-5.6.8.rpm
rpm -ivh elasticsearch-5.6.8.rpm
配置文件说明:
[root@node01 ~]# rpm -ql elasticsearch
/etc/elasticsearch/elasticsearch.yml 主配置文件
/etc/elasticsearch/jvm.options 配置参数文件
/etc/elasticsearch/log4j2.properties 日志文件
/etc/elasticsearch/scripts 存放脚本
更改elasticsearch.yml文件
cd /etc/elasticsearch/
vim elasticsearch.yml
cluster.name: myels #集群名称,默认为my-application,可以根据需求自定义
node.name: node01.magedu.com #当前成员节点名称,用于成员节点发现,建议与当前主机名保持一致
#node.attr.rack: r1 #Elasticsearch具备机架感知功能,当前成员节点处于哪个机架。该功能需要开发程序以后进行定义,这里只做说明,并不启用
path.data: /els/data #定义数据存放路径
path.logs: /els/logs #定义日志存放路径
#bootstrap.memory_lock: true #在bootstrap锁定相关内存,实验环境不用开启
network.host: 192.168.32.151 #定义监听哪些地址并向客户端提供服务,设为当前主机对外通信的地址
http.port: 9200 监听并向客户端提供服务的端口
discovery.zen.ping.unicast.hosts: ["node01.magedu.com", "node02.magedu.com", "node03.magedu.com"] #成员关系判定,通过单播方式判定主机是否在线,在中括号内写入主机名或ip地址
discovery.zen.minimum_master_nodes: 1 #最少有几个主节点,一般情况下,只需要一个主节点。
#注意:该主节点是通过9300端口判定集群内部事务的主节点,用于协调集群内部事务的leader,与客户端访问的主副节点没有任何关系
更改jvm.options文件
vim jvm.options
-Xms1g #堆内存初始空间大小
-Xmx1g #堆内存空间最大值
#注意:Elasticsearch要求二者的值必须一致,其大小可以根据服务器内存大小进行调整
## GC configuration #垃圾回收算法,标记清除算法
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
创建存储日志和数据的目录,该目录要求elasticsearch用户具有写权限
mkdir -p /els/{data,logs}
chown -R elasticsearch.elasticsearch /els/*
验证权限是否设置正确
ll /els/
启动服务
systemctl start elasticsearch.service
把更改过的配置文件分别复制到主机192.168.32.152和主机192.168.32.153上
scp elasticsearch.yml jvm.options node02:/etc/elasticsearch/
scp elasticsearch.yml jvm.options node03:/etc/elasticsearch/
注意:复制到其他节点后,要更改各个主机配置文件中的节点成员名称和监听的ip地址
主机192.168.32.152上
cd /etc/elasticsearch/
vim elasticsearch.yml
node.name: node02.magedu.com
network.host: 192.168.32.152
创建存储日志和数据的目录,该目录要求elasticsearch用户具有写权限
mkdir -p /els/{data,logs}
chown -R elasticsearch.elasticsearch /els/*
验证权限是否设置正确
ll /els/
启动服务
systemctl start elasticsearch.service
主机192.168.32.153上
cd /etc/elasticsearch/
vim elasticsearch.yml
node.name: node03.magedu.com
network.host: 192.168.32.153
创建存储日志和数据的目录,该目录要求elasticsearch用户具有写权限
mkdir -p /els/{data,logs}
chown -R elasticsearch.elasticsearch /els/*
验证权限是否设置正确
ll /els/
启动服务
systemctl start elasticsearch.service
查看监听端口9200,9300
9300端口用于内部事务协调,判定谁是leader,当前集群状态是什么,该端口与客户端没有关系
9200端口是向客户端提供服务的,用户可以向里面存文档,也可以通过它执行搜索操作- Elasticsearch相关命令介绍:
curl http://node03:9200/后跟以下划线开头的url会显示相应的结果
如:curl http://node03:9200/\_cat 查看集群内部信息
curl http://node03:9200/\_search
curl http://node03:9200/\_cluster
示例:
[root@node01 ~]# curl http://node03:9200/_cat
=^.^=
/_cat/allocation
/_cat/shards
/_cat/shards/{index}
/_cat/master #显示集群成员主节点
/_cat/nodes #显示集群成员总数
/_cat/tasks
/_cat/indices #显示集群内部有几个索引存在,在后面跟具体哪个索引,就可查看该索引具体信息
/_cat/indices/{index}
/_cat/segments
/_cat/segments/{index}
/_cat/count
/_cat/count/{index}
/_cat/recovery
/_cat/recovery/{index}
/_cat/health #查看健康状态
/_cat/pending_tasks
/_cat/aliases
/_cat/aliases/{alias}
/_cat/thread_pool #查看集群中有多少个线程池在工作
/_cat/thread_pool/{thread_pools}
/_cat/plugins #查看集群中有多少个插件
/_cat/fielddata
/_cat/fielddata/{fields}
/_cat/nodeattrs
/_cat/repositories
/_cat/snapshots/{repository}
/_cat/templates #查看集群中有多少个模板
[root@node01 ~]# curl http://node03:9200/_cat/nodes #查看elasticsearch集群各节点信息
192.168.32.151 14 84 0 0.08 0.03 0.05 mdi - node01.magedu.com
192.168.32.152 20 82 1 0.00 0.02 0.05 mdi * node02.magedu.com
192.168.32.153 24 87 1 0.00 0.03 0.06 mdi - node03.magedu.com
注意:带有*的表示为主节点,该主节点与客户端没有关系,是集群内部事务协调生成的- 获取文档查询格式:
示例:
curl http://node02:9200/myindex/setudents/1
{"error":{"root_cause":[{"type":"index_not_found_exception","reason":"no such index","resource.type":"index_expression","resource.id":"myindex","index_uuid":"_na_","index":"myindex"}],"type":"index_not_found_exception","reason":"no such index","resource.type":"index_expression","resource.id":"myindex","index_uuid":"_na_","index":"myindex"},"status":404}
curl http://node02:9200/myindex/setudents/1?pretty=true #以美观的方式展示结果
或者curl http://node02:9200/myindex/setudents/1?pretty
curl http://node02:9200/myindex/setudents/1?jq
注意:jq需要先安装才能使用(epel源)
{
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index",
"resource.type" : "index_expression",
"resource.id" : "myindex",
"index_uuid" : "_na_",
"index" : "myindex"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index",
"resource.type" : "index_expression",
"resource.id" : "myindex",
"index_uuid" : "_na_",
"index" : "myindex"
},
"status" : 404
}该结果意为没有找到搜索的文档
- 创建文档:
示例:
curl -XPUT http://node02:9200/myindex/setudents/1 -d '
> {"name":"Guo Jin","age":17,"Kongfu":"Xianglong Shiba Zhang"}'
{"_index":"myindex","_type":"setudents","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":2,"failed":0},"created":true}
-XPUT是指如果不存在将会自动创建文档,类型
-d 指定文档内容,内容必须是json格式
"_index":"myindex" 索引
"_type":"setudents" 类型
"_id":"1" id号
"_version":1 版本
"result":"created" 创建结果
"_shards":{"total":2,"successful":2,"failed":0}, 创建两个分片,默认创建分片为一主一副
"created":true- 再次进行文档查询:
示例:
[root@node01 ~]# curl http://node02:9200/myindex/setudents/1?pretty
{
"_index" : "myindex",
"_type" : "setudents",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name" : "Guo Jin",
"age" : 17,
"Kongfu" : "Xianglong Shiba Zhang"
}
}-
修改文档 使用POST方法
-
删除文档 使用DELETE方法
-
获取索引信息:
示例:
curl -XGET http://node02:9200/_cat/indices
green open myindex 7Mt9YJ-hTgG4FE12sOgjKQ 5 1 1 0 10.1kb 5kb- 查看elasticsearch集群上分片分布情况:
示例:
curl -XGET http://node02:9200/\_cat/shards
[root@node01 ~]# curl -XGET http://node02:9200/\_cat/shards
myindex 3 p STARTED 1 4.4kb 192.168.32.151 node01.magedu.com
myindex 3 r STARTED 1 4.4kb 192.168.32.152 node02.magedu.com
myindex 4 r STARTED 0 162b 192.168.32.151 node01.magedu.com
myindex 4 p STARTED 0 162b 192.168.32.152 node02.magedu.com
myindex 2 r STARTED 0 162b 192.168.32.151 node01.magedu.com
myindex 2 p STARTED 0 162b 192.168.32.153 node03.magedu.com
myindex 1 p STARTED 0 162b 192.168.32.152 node02.magedu.com
myindex 1 r STARTED 0 162b 192.168.32.153 node03.magedu.com
myindex 0 p STARTED 0 162b 192.168.32.151 node01.magedu.com
myindex 0 r STARTED 0 162b 192.168.32.153 node03.magedu.com
注意:一个索引默认有5个分片,每个有主副之分,因此有10个分片
p 是指主分片,r 是指副本分片- 界定搜索范围:
示例:
/\_search:搜索所有的索引和类型;
/INDEX_NAME/\_search:搜索指定的单个索引;
/INDEX1,INDEX2/\_search:搜索指定的多个索引;
/s\*/\_search:搜索所有以s开头的索引;
/INDEX\_NAME/TYPE\_NAME/\_search:搜索指定的单个索引的指定类型;- 搜索数据中带有Zhang(掌法)的关键字的信息:
示例:
curl -XGET http://node01:9200/\_search?q=Kongfu:Zhang
?后是指搜索条件- 安装jq,jq是用于处理json格式数据的处理器并以美观的方式显示出来
示例:
yum -y install jq
curl -s -XGET http://node01:9200/_search?q=Kongfu:jian | jq . #jq .表示显示整个文档中与jian有关的信息
[root@node01 ~]# curl -s -XGET http://node01:9200/_search?q=Kongfu:jian | jq .
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
curl -s -XGET http://node01:9200/_search?q=Kongfu:jian | jq .took
#表示只显示took信息
curl -s -XGET http://node01:9200/myindex/_search?q=Kongfu:jian | jq . #表示只在索引myindex中搜索
curl -s -XGET http://node01:9200/myindex/students/_search?q=Kongfu:jian | jq .
#表示在索引myindex中students类型中搜索
curl -s -XGET http://node01:9200/my*/students/_search?q=Kongfu:jian | jq .
#表示在以my开头的索引中搜索5.2 Logstash配置介绍
-
Logstash支持三类插件
1、输入插件 input
2、过滤器插件 filter
3、输出插件 output -
两种用法:
1、当作agent,用于收集日志,即统一日志存储分析平台
2、站内搜索,用于搜索内部文章 -
应用场景:
以tomcat为例,在tomcat内部每个主机节点上都装有logstash,用于收集日志,分析,并装入Elasticsearch主机,但是这样一来有以下缺点:
(1)每个主机节点Logstash配置必须一致,如果某个节点配置不同,那么转换的数据格式也会不同,Elasticsearch服务器接收到不同格式的数据,处理起来相当不便
(2)如果每个Logstash都要向Elasticsearch服务器装入数据,那么Elasticsearch服务器要接收很多连接,对服务器造成很大压力
因此,要在Elasticsearch服务器前端添加一个Logstash server,接收所有tomcat内部主机节点的Logstash发送的数据。在这种场景下,tomcat主机节点上的Logstash只用于收集日志,不在本地完成数据转换,而是统一发送给Logstash server,由其完成数据格式转换,然后统一装入Elasticsearch服务器。
这样一来,tomcat主机节点上的Logstash就相当于一个agent,只用于收集tomcat主机节点日志,发送给Logstash server,在本地统一进行格式转换,然后统一发送给Elasticsearch服务
但是,由于Logstash太过重量级,因此可以使用一个轻量级应用beats(filebeat)代替Logstash收集日志 -
beats工具
轻量级数据传输工具 -
beats家族套件:
Filebeat 专门从文件中抽取数据并发给Logstash server
Metricbeat 收集指标数据,比如cpu的各种指标(利用率,空闲率等)
Packetbeat 对网络通信流量抓包分析
Winlogbeat 专门用于windows服务器上收集事件查看器中的日志
Auditbeat 收集审计日志
Heartbeat 探测服务器健康状态
Logstash配置
示例:
在主机192.168.32.154上
安装httpd服务
yum -y install httpd
启动httpd服务
systemctl start httpd
生成测试页
cd /var/www/html
for i in {1..20};do echo "Page $i" > ./test$i.html;done;
更改配置文件中的日志记录格式:记录客户端访问ip地址
vim /etc/httpd/conf/httpd.conf
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
重启httpd服务
systemctl restart httpd
在客户端主机进行访问测试
curl -H "X-Forwarded-For:1.1.1.1" http://192.168.32.154/test1.html #添加自定义头部信息
使用循环模拟从不同ip地址访问目标网站,以便于生成日志
while true;do curl -H "X-Forwarded-For:$[$RANDOM%223+1].$[$RANDOM%255].$[$RANDOM%255].$[$RANDOM%255]" http://192.168.32.154/test$[$RANDOM%20+1].html;sleep 0.5;done;
注意:在使用logstash命令调用配置文件时,该命令要一直执行,logstash主机才会显示结果
在192.168.32.154主机上
下载并安装Logstash软件收集日志
由于Logstash是基于java开发的,因此需要先安装jdk
yum -y install java-1.8.0-openjdk
rpm -ivh logstash-5.6.8.rpm
配置文件:
vim /etc/logstash/logstash.yml
path.data: /var/lib/logstash #logstash本地暂存数据的目录
path.config: /etc/logstash/conf.d #在哪加载配置文件,包括输入插件配置文件,过滤器插件配置文件,输出插件配置文件等
主程序文件:
/usr/share/logstash/bin/logstash
该文件不在PATH环境变量中,因此为了便于管理,把该路径加入PATH环境变量中
编辑配置环境变量
vim /etc/profile.d/logstash.sh
export PATH=$PATH:/usr/share/logstash/bin
启用该文件
source /etc/profile.d/logstash.sh- logstash命令常用选项:
-f 加载特定的配置文件
-t 配置文件语法测试
-r 如果配置文件发生改变,会自动执行reload
Logstash配置文件示例
- 配置logstash配置文件
示例:
cd /etc/logstash/conf.d #子配置文件目录
vim stdin_stdout.conf
input { #定义输入插件
stdin {}
}
output { #定义输出插件
stdout {
codec => rubydebug #指定输出编码器,输出为rubydebug格式,会自动转换为json格式
}
}
logstash -f stdin_stdout.conf -t #-f加载指定配置文件stdin_stdout.conf,-t检查语法是否正确
注意:此时提示找不到标准的logstash.yml文件,这是因为使用-f选项指定了配置文件,阻碍了查找标准的配置文件,因此可以忽略
去掉-t选项直接执行命令
注意:在使用logstash命令调用配置文件时,客户端主机的循环命令要一直执行,logstash主机才会显示结果
[root@master conf.d]# logstash -f stdin_stdout.conf
The stdin plugin is now waiting for input: #等待输入信息
hello logstash #输入信息
{ #显示结果为json格式
"@timestamp" => 2018-12-04T07:12:14.134Z, #事件生成的时间戳
"@version" => "1", #文档版本号
"host" => "master.magedu.com", #由哪个主机生成
"message" => "hello logstash" #输入信息是什么
}- 把httpd主机上生成的日志文件当做输入内容:
示例:
更改logstash子配置文件
vim file_stdout.conf
input {
file {
path => "/var/log/httpd/access_log" #指定读取文件的路径
start_position => "beginning" #指定文件开始位置
}
}
output {
stdout {
codec => rubydebug #指定输出编码器,输出为rubydebug格式,会自动转换为json格式
}
}
检测指定配置文件语法是否正确
logstash -f file_stdout.conf -t
加载指定文件
logstash -f file_stdout.conf
显示结果:
{
"path" => "/var/log/httpd/access_log",
"@timestamp" => 2018-12-04T08:10:57.188Z,
"@version" => "1",
"host" => "master.magedu.com",
"message" => "122.111.114.202 - - [04/Dec/2018:16:10:25 +0800] \"GET /test17.html HTTP/1.1\" 200 8 \"-\" \"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\""
}
{
"path" => "/var/log/httpd/access_log",
"@timestamp" => 2018-12-04T08:10:57.189Z,
"@version" => "1",
"host" => "master.magedu.com",
"message" => "61.155.73.183 - - [04/Dec/2018:16:10:26 +0800] \"GET /test2.html HTTP/1.1\" 200 7 \"-\" \"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\""
}- 显示结果中message信息每个字段易读性不强,因此可以切分开,分字段显示,更容易查看
使用模式匹配去除每个字段的值,进行显示
系统定义的模式匹配文件
示例:
/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns/grok-patterns
注意:可以根据此文件中事先定义好的模式进行查找自己所需的字段
示例:这里只显示文件部分内容
[root@master conf.d]# less /usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
EMAILLOCALPART [a-zA-Z][a-zA-Z0-9_.+-=:]+
EMAILADDRESS %{EMAILLOCALPART}@%{HOSTNAME}
INT (?:[+-]?(?:[0-9]+))
BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})
BASE16NUM (?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+))
BASE16FLOAT \b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\b- 以httpd协议模式匹配文件:
示例:
/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns/httpd
[root@master conf.d]#cat /usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns/httpd
HTTPDUSER %{EMAILADDRESS}|%{USER}
HTTPDERROR_DATE %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{YEAR}
# Log formats
HTTPD_COMMONLOG %{IPORHOST:clientip} %{HTTPDUSER:ident} %{HTTPDUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
HTTPD_COMBINEDLOG %{HTTPD_COMMONLOG} %{QS:referrer} %{QS:agent} #http combindlog日志格式,匹配每一行的日志信息,会自动剪出来每个字段并加上key
# Error logs
HTTPD20_ERRORLOG \[%{HTTPDERROR_DATE:timestamp}\] \[%{LOGLEVEL:loglevel}\] (?:\[client %{IPORHOST:clientip}\] ){0,1}%{GREEDYDATA:message}
HTTPD24_ERRORLOG \[%{HTTPDERROR_DATE:timestamp}\] \[%{WORD:module}:%{LOGLEVEL:loglevel}\] \[pid %{POSINT:pid}(:tid %{NUMBER:tid})?\]( \(%{POSINT:proxy_errorcode}\)%{DATA:proxy_message}:)?( \[client %{IPORHOST:clientip}:%{POSINT:clientport}\])?( %{DATA:errorcode}:)? %{GREEDYDATA:message} #http2.4的errorlog日志格式
HTTPD_ERRORLOG %{HTTPD20_ERRORLOG}|%{HTTPD24_ERRORLOG}
# Deprecated
COMMONAPACHELOG %{HTTPD_COMMONLOG}
COMBINEDAPACHELOG %{HTTPD_COMBINEDLOG} #调用http combindlog日志格式- commonlog日志格式
combindlog是commonlog的扩展版
示例:
HTTPD_COMMONLOG #commonlog日志格式
%{IPORHOST:clientip} 客户端地址,客户端主机名
%{HTTPDUSER:ident}
%{HTTPDUSER:auth} 认证时的用户名
\[%{HTTPDATE:timestamp}\] 访问日期时间,默认为格林尼治时间
"(?:%{WORD:verb} 请求方法
%{NOTSPACE:request} 请求url
(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" 协议版本
%{NUMBER:response} 响应码
(?:%{NUMBER:bytes}|-) 响应长度
HTTPD_COMBINEDLOG #combind日志格式
%{HTTPD_COMMONLOG}
%{QS:referrer} 从哪跳转过来的
%{QS:agent} 客户端浏览器类型- grok中的match指令
能够实现基于hash的方式让我们自定义指定模式的方式把每一行信息拿出来做独立切割
如上面显示结果中的message字段,对日志中的每一行使用模式进行切分,使用match把message字段中的内容,根据模式进行处理、分析和切分,从而完成文档化 - 在配置文件中增加过滤器插件:
示例:
调用grok插件对日志进行模式匹配并文档化显示
vim file_grok_stdout.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" } #调用combinedlog日志格式
}
}
output {
stdout {
codec => rubydebug
}
}
调用该配置文件
logstash -f file_grok_stdout.conf
显示结果:
{
"request" => "/test16.html",
"agent" => "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"message" => "65.86.19.221 - - [04/Dec/2018:16:18:24 +0800] \"GET /test16.html HTTP/1.1\" 200 8 \"-\" \"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"path" => "/var/log/httpd/access_log",
"referrer" => "\"-\"",
"@timestamp" => 2018-12-04T08:55:48.789Z,
"response" => "200",
"bytes" => "8",
"clientip" => "65.86.19.221",
"@version" => "1",
"host" => "master.magedu.com",
"httpversion" => "1.1",
"timestamp" => "04/Dec/2018:16:18:24 +0800"
}
注意:结果显示中为把message字段中的内容进行切分并单独显示出来- 移除message字段:
示例:
使用remove插件 (过滤器插件)
vim file_grok_stdout.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" } #调用combinedlog日志格式
remove_field => "message" #调用remove插件
}
}
output {
stdout {
codec => rubydebug
}
}
调用该配置文件
logstash -f file_grok_stdout.conf
显示结果:
{
"request" => "/test10.html",
"agent" => "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"path" => "/var/log/httpd/access_log",
"referrer" => "\"-\"",
"@timestamp" => 2018-12-04T09:11:54.993Z,
"response" => "200",
"bytes" => "8",
"clientip" => "66.160.214.145",
"@version" => "1",
"host" => "master.magedu.com",
"httpversion" => "1.1",
"timestamp" => "04/Dec/2018:16:20:59 +0800"
}发现结果中存在两个时间戳@timestamp和timestamp
@timestamp是指logstash读取日志时生成的时间点
timestamp是指客户端访问网页时日志生成的时间点
对于我们来说,客户访问网页时生成的时间点才是真正的时间,但@timestamp是用于时间序列分析时使用的时间,可用于生成时间序列数据项,因此该项不能删除
解决方法:
把日志生成的时间点替换为logstash读取日志时的时间点,然后删除掉timestamp这一项。这样@timestamp显示的时间是客户端访问网页时生成的真正的时间,并且保留了@timestamp选项
- 调用filter插件中的Date filter plugin插件
示例:
Date插件 (过滤器插件)
该插件允许我们能够定义@timestamp的时间替换为另一个字段的时间
vim input_file_output.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"] #使用timestamp的时间替换@timestamp
remove_field => "timestamp" #调用remove插件删除掉timestamp项
}
}
output {
stdout {
codec => rubydebug
}
}
显示结果: timestamp选项已经删除,@timestamp时间已经替换为timestamp时间
{
"request" => "/test17.html",
"agent" => "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"path" => "/var/log/httpd/access_log",
"referrer" => "\"-\"",
"@timestamp" => 2018-12-04T08:14:30.000Z,
"response" => "200",
"bytes" => "8",
"clientip" => "203.81.56.73",
"@version" => "1",
"host" => "master.magedu.com",
"httpversion" => "1.1"
}-
geoip过滤器插件
能够实现取出ip字段,并对其做地理位置归属地的分析和记录
全球ip地址是由互联网数字名称分配机构负责分配的,每当一个ip地址被分配和使用时,会记录ip地址的归属方是谁
如何分析公网ip地址归属呢,只需要到IANA,拿到ip地址分配库,每一个ip地址都当做一个键,查找数据库中地址注册人的信息,包括其所属的国家、省份、城市,进而查找到该城市所在的经度和纬度,完成ip地址的定位 -
geoip插件根据指定的字段,获取其中的ip地址与数据库进行比对,获取到该ip地址所在的具体位置,如果不存在则返回错误
-
geoip用到的数据库,由Maxmind提供
-
Maxmind专门包装输出互联网上每一个地址注册者注册身份的地址库
-
Maxmind有两种格式的地址库:
精细版本 需要付费
简装版 免费使用 -
Maxmind官网:www.maxmind.com
-
需要把maxmind数据库下载到本地才能使用
简装版软件包:GeoLite2-City.tar.gz
下载地址:http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.tar.gz -
需要指定数据项:
database 指明maxmind格式的database存放路径
source 打算从已有数据项当中的哪一个字段读取ip地址,获取到ip地址以后转换为什么格式
示例:
vim input_file_output-2.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip" #生成新字段,把原来的clientip字段分析以后,把结果保存在geoip的字段中,这个字段值是一个json格式的子文档,包含该IP所在的国家、省份、城市以及城市的经纬度等
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb" #指明数据库文件路径
}
}
output {
stdout {
codec => rubydebug
}
}
注意:由于maxmind数据库每周都会进行更新,因此我们应该做计划任务,在该数据库进行更新以后自动下载到本地并展开,推荐使用软链接指向该数据库,在版本更新时只需更改软链接即可完成版本替换- Maxmind软件包安装
示例:
下载软件包到本地并解压
tar xf GeoLite2-City.tar.gz
创建存放maxmind数据库的目录
mkdir /etc/logstash/maxmind/
把数据库复制到/etc/logstash/maxmind/目录下
cp -r GeoLite2-City_20181127/ /etc/logstash/maxmind/
创建软链接,方便版本更新
cd /etc/logstash/maxmind/
ln -sv GeoLite2-City_20181127/GeoLite2-City.mmdb ./
配置文件语法检测
cd /etc/logstash/conf.d/
logstash -f input_file_output-2.conf -t
读取配置文件并生成结果
logstash -f input_file_output-2.conf
显示结果:
{
"request" => "/test17.html",
"agent" => "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"geoip" => {
"timezone" => "Europe/London", #显示时区为伦敦
"ip" => "178.22.19.175",
"latitude" => 51.4964,
"country_name" => "United Kingdom", #国家名称
"country_code2" => "GB", #国家代码
"continent_code" => "EU", #国家代码
"country_code3" => "GB", #国家代码
"location" => {
"lon" => -0.1224, #经度
"lat" => 51.4964 #纬度
},
"longitude" => -0.1224
},
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"path" => "/var/log/httpd/access_log",
"referrer" => "\"-\"",
"@timestamp" => 2018-12-04T08:12:44.000Z,
"response" => "200",
"bytes" => "8",
"clientip" => "178.22.19.175",
"@version" => "1",
"host" => "master.magedu.com",
"httpversion" => "1.1"
}fields插件可以只保留有用字段,去除其他不需要的字段
Mutate插件可以根据需求操作字段,包括重命名,移除,替换,修改字段
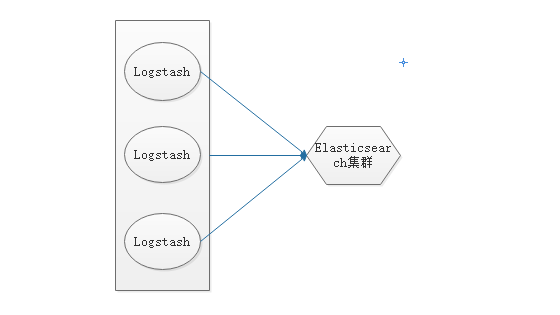
Logstash+Elasticsearch配置
-
架构图如下所示:
-
输出插件
Elasticsearch输出插件
hosts 指定Elasticsearch主机在哪,为uri格式
index 指定索引名称
document_type 指定文档类型
document_id 指定文档id
http_compression 保存到Elasticsearch中以后,传输过程是否压缩
password 如果实用认证,认证是的用户名和密码
hosts格式如下:
"127.0.0.1" 单个地址
["127.0.0.1:9200","127.0.0.2:9200"] 多个地址
["http://127.0.0.1"] 带有协议的地址
["https://127.0.0.1:9200"] 带有协议和端口的地址
["https://127.0.0.1:9200/mypath"] 带有协议端口和url的地址配置文件:
vim file-els.conf
input {
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
output { #配置输出插件
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200","http://node03.magedu.com:9200/"] #指定Elasticsearch主机位置
index => "logstash-%{+YYYY.MM.dd}" #指定文档放在哪个索引中,并指定索引的格式
document_type => "httpd_access_logs" #指定放在哪个类型中
}
}
语法检测:
logstash -f file-els.conf -t
加载配置文件:
logstash -f file-els.conf此时,日志信息将会被保存到Elasticsearch主机上,而不会打印在屏幕上,因此需要在Elasticsearch主机上查看日志文件
在主机192.168.32.151上
curl http://node01:9200/_cat/indices
green open logstash-2018.12.04 saTQbWL-SgOwNuv_MbModQ 5 1 30 0 575.1kb 300.1kb - 搜索以logstash开头的索引中ip地址为141.62.86.133的信息,并使用jq以美观方式显示
示例:
[root@node01 logs]# curl http://node01:9200/logstash-*/_search?q=clientip:143.19.222.49 |jq . #注意:如果显示没有命中,ip地址143.19.222.49可以查看访问日志中的ip地址
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 842 100 842 0 0 44789 0 --:--:-- --:--:-- --:--:-- 46777
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 2.5902672,
"hits": [
{
"_index": "logstash-2018.12.04",
"_type": "httpd_access_logs",
"_id": "AWd5oYZ9sJLcuPzP_EE1",
"_score": 2.5902672,
"_source": {
"request": "/test21.html",
"agent": "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"geoip": {
"ip": "143.19.222.49",
"latitude": 37.751,
"country_name": "United States",
"country_code2": "US",
"continent_code": "NA",
"country_code3": "US",
"location": {
"lon": -97.822,
"lat": 37.751
},
"longitude": -97.822
},
"auth": "-",
"ident": "-",
"verb": "GET",
"path": "/var/log/httpd/access_log",
"referrer": "\"-\"",
"@timestamp": "2018-12-04T14:31:27.000Z",
"response": "404",
"bytes": "209",
"clientip": "143.19.222.49",
"@version": "1",
"host": "master.magedu.com",
"httpversion": "1.1"
}
}
]
}
}- 搜索以logstash开头的索引中response的值为404的信息:
示例:
此时在192.168.32.151主机使用循环语句继续访问httpd服务生成日志
while true;do curl -H "X-Forwarded-For:$[$RANDOM%223+1].$[$RANDOM%225].$[$RANDOM%225].$[$RANDOM%225]" http://192.168.32.154/test$[$RANDOM%20+1].html;sleep 0.5;done;
把$RANDOM%20+1更改$RANDOM%25+1,则表示有些网页访问不到,就会出现404代码
[root@node01 logs]# curl http://node01:9200/logstash-*/_search?q=response:404 |jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7549 100 7549 0 0 8795 0 --:--:-- --:--:-- --:--:-- 8788
{
"took": 850,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 19,
"max_score": 2.5389738,
"hits": [
{
"_index": "logstash-2018.12.04",
"_type": "httpd_access_logs",
"_id": "AWd5oM1MsJLcuPzP_EEn",
"_score": 2.5389738,
"_source": {
"request": "/test23.html",
"agent": "\"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.27.1 zlib/1.2.3 libidn/1.18 libssh2/1.4.2\"",
"geoip": {
"ip": "138.33.42.97",
"latitude": 37.751,
"country_name": "United States",
"country_code2": "US",
"continent_code": "NA",
"country_code3": "US",
"location": {
"lon": -97.822,
"lat": 37.751
},
"longitude": -97.822
},
"auth": "-",
"ident": "-",
"verb": "GET",
"path": "/var/log/httpd/access_log",
"referrer": "\"-\"",
"@timestamp": "2018-12-04T14:30:40.000Z",
"response": "404",
"bytes": "209",
"clientip": "138.33.42.97",
"@version": "1",
"host": "master.magedu.com",
"httpversion": "1.1"
}
}
}Filebeat配置介绍
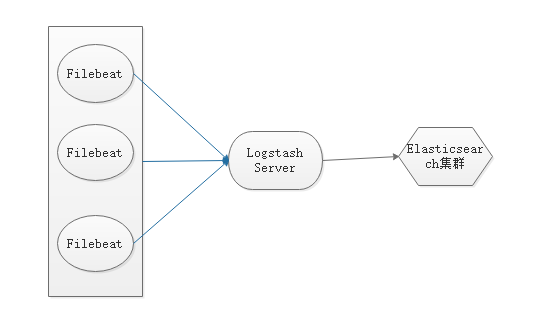
-
使用beats(filebeat)收集日志,把日志发送给Logstash server
即:filebeat --> logstash --> elasticsearch
注意:要更改输入和输出的主机 -
架构图若下所示:
-
Filebeat安装
示例:
在192.168.32.154主机上安装filebeat代替原来的logstash收集日志
安装filebeat:
rpm -ivh filebeat-5.6.8-x86_64.rpm
配置文件
/etc/filebeat/filebeat.full.yml 配置文件完整示例
/etc/filebeat/filebeat.yml 主配置文件
/usr/share/filebeat/bin/filebeat 主程序
配置:
配置之前先对其做备份
cp filebeat.yml{,.bak}
对配置文件进行如下配置:
vim /etc/filebeat/filebeat.yml
- /var/log/httpd/access_log #指定读取日志的路径
#output.elasticsearch: #filebeat默认把数据输出到elasticsearch中,需要注释掉该行
#hosts: ["localhost:9200"] #监听端口也需要注释掉
output.logstash: #启用该项,去掉开头的注释符,把数据输出到logstash中
hosts: ["192.168.32.154:5044"] #启用该项,去掉开头注释符,指定logstash主机监听的地址和端口
配置文件内容如下:
#=========================== Filebeat prospectors ============================= #定义从哪个文件获取数据
filebeat.prospectors:
# Each - is a prospector. Most options can be set at the prospector level, so
# you can use different prospectors for various configurations.
# Below are the prospector specific configurations.
- input_type: log #数据类型必须是日志
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/httpd/access_log #指定读取日志的路径
#- c:\programdata\elasticsearch\logs\*
# Exclude lines. A list of regular expressions to match. It drops the lines that are
# matching any regular expression from the list.
#exclude_lines: ["^DBG"] #指明排除日志的哪些特殊的行,比如DBG开头的行
# Include lines. A list of regular expressions to match. It exports the lines that are
# matching any regular expression from the list.
#include_lines: ["^ERR", "^WARN"] #指定日志只包含哪些特殊的行,比如ERR、WARN开头的行,这些在读取错误日志中有用。应用场景:服务器故障监控或者问题监控时
#================================ Outputs ===================================== #表示加载的数据输出到哪里去
# Configure what outputs to use when sending the data collected by the beat.
# Multiple outputs may be used.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch: #filebeat默认把数据输出到elasticsearch中,需要注释掉该行
# Array of hosts to connect to.
#hosts: ["localhost:9200"] #监听端口也需要注释掉
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
output.elasticsearch filebeat默认把数据输出到elasticsearch中
注意:filebeat加载的信息默认不能输出到elasticsearch中,因为其输出的数据没有被文档化.
#需要使用logstash中的gork把整个日志切割成多段,便于搜索,因此我们需要把输出数据传输给logstash,这里需要把output.elasticsearch注释掉
#----------------------------- Logstash output --------------------------------
output.logstash: #启用该项,去掉开头的注释符,把数据输出到logstash中
# The Logstash hosts
hosts: ["192.168.32.154:5044"] #启用该项,去掉开头注释符,指定logstash主机监听的地址和端口
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] #使用ssl认证时,指定证ca书路径,此处没有启用,无需开启
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem" #使用ssl认证时,指定私钥路径,此处没有启用,无需开启
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key #使用ssl认证时,指定证书路径,此处没有启用,无需开启
#================================ Logging ===================================== 日志相关配置
# Sets log level. The default log level is info.
# Available log levels are: critical, error, warning, info, debug
#logging.level: debug
# At debug level, you can selectively enable logging only for some components.
# To enable all selectors use ["*"]. Examples of other selectors are "beat",
# "publish", "service".
#logging.selectors: ["*"]这里,对filebeat的配置已经完成
Filbeat+Logstash+Elasticsearch配置
下面对logstash进行相关配置(logstash仍在192.168.32.154主机上)
Logstash子配置文件如下:
cd /etc/logstash/conf.d
cp file_els.conf beats_els.conf
vim beats_els.conf
input {
beats{
port => 5044 #指定监听的端口,不指定ip地址是指默认监听本机所有端口
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200","http://node03.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "httpd_access_logs"
}
}
使用logstash调用配置文件
logstash -f beats_els.conf 开启logstash,不要退出该程序,再次开启一个窗口查看5044端口是否启用
启动filebeat服务
systemctl start filebeat
查看filebeat进程是否开启
ps aux |grep filebeat
在192.168.32.151主机使用循环语句继续访问httpd服务生成日志
while true;do curl -H "X-Forwarded-For:$[$RANDOM%223+1].$[$RANDOM%225].$[$RANDOM%225].$[$RANDOM%225]" http://192.168.32.154/test$[$RANDOM%25+1].html;sleep 0.5;done;
在192.168.32.151住上查询日志结果信息
curl http://node01:9200/logstash-*/_search?q=response:404 | jq . #这里只贴出部分内容
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 8942 100 8942 0 0 395k 0 --:--:-- --:--:-- --:--:-- 415k
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 250,
"max_score": 2.4922059,
"hits": [
{
"_index": "logstash-2019.03.18",
"_type": "httpd_access_logs",
"_id": "AWmRLhTUXqBOXkKLhWx6",
"_score": 2.4922059,
"_source": {
"request": "/test24.html",
"agent": "\"curl/7.29.0\"",
"geoip": {
"ip": "151.165.219.164",
"latitude": 37.751,
"country_name": "United States",
"country_code2": "US",
"continent_code": "NA",
"country_code3": "US",
"location": {
"lon": -97.822,
"lat": 37.751
},
"longitude": -97.822
},
"offset": 106889,
"auth": "-",
"ident": "-",
"input_type": "log",
"verb": "GET",
"source": "/var/log/httpd/access_log",
"type": "log",
"tags": [
"beats_input_codec_plain_applied"
],
"referrer": "\"-\"",
"@timestamp": "2019-03-18T11:00:47.000Z",
"response": "404",
"bytes": "209",
"clientip": "151.165.219.164",
"@version": "1",
"beat": {
"name": "master.magedu.com",
"hostname": "master.magedu.com",
"version": "5.6.8"
},
"host": "master.magedu.com",
"httpversion": "1.1"
}
},
移除显示结果中的beat字段
vim beats_els.conf
input {
beats{
port => 5044
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message","beat"] #添加beat字段
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02
.magedu.com:9200","http://node03.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "httpd_access_logs"
}
}Filebeat+Redis+Logstash+Elasticsearch配置
-
借助redis作为消息队列,接收filebeat发送过来的数据,然后redis把数据传输给logstash server
即:filebeat --> 消息队列(redis) --> logstash server --> elasticsearch -
架构图如下所示:
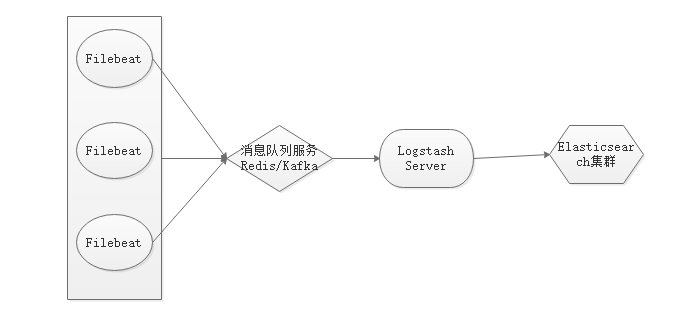
-
配置如下:
停止logstash服务(停止logstash调用配置文件即可)
停止filebeat服务
systemctl stop filebeat
这里,我们把192.168.32.154主机作为消息队列,在该主机上安装redis
yum -y install redis
注意:由于filebeat需要把数据输出到redis,但filebeat配置文件filebeat.yml中默认没有输出到redis的配置项。
解决方法:在filebeat的配置文件的完整示例/etc/filebeat/filebeat.full.yml中有redis的相关配置
如下所示:vim /etc/filebeat/filebeat.yml #------------------------------- Redis output ---------------------------------- #output.redis: #输出数据到redis # Boolean flag to enable or disable the output module. #enabled: true #启用该插件 # The list of Redis servers to connect to. If load balancing is enabled, the # events are distributed to the servers in the list. If one server becomes # unreachable, the events are distributed to the reachable servers only. #hosts: ["localhost:6379"] #指明redis主机的位置,包括ip地址和端口号 # The Redis port to use if hosts does not contain a port number. The default # is 6379. #port: 6379 # The name of the Redis list or channel the events are published to. The # default is filebeat. #key: filebeat #使用哪个key保存数据 # The password to authenticate with. The default is no authentication. #password: #做认证时的密码 # The Redis database number where the events are published. The default is 0. #db: 0 #存放在哪个redis数据库中 # The Redis data type to use for publishing events. If the data type is list, # the Redis RPUSH command is used. If the data type is channel, the Redis # PUBLISH command is used. The default value is list. #datatype: list #数据类型 # The number of workers to use for each host configured to publish events to # Redis. Use this setting along with the loadbalance option. For example, if # you have 2 hosts and 3 workers, in total 6 workers are started (3 for each # host). #worker: 1 #启动几个worker进程与redis进行交互
编辑redis配置文件
vim /etc/redis.conf
bind 0.0.0.0
requirepass magedu.com启动redis
systemctl start redis
查看redis监听端口6379是否启用
- 配置filebeat配置文件,把/etc/filebeat/filebeat.full.yml文件中redis的相关配置段复制到/etc/filebeat/filebeat.yml中,在Logstashoutput配置段之后添加以下内容并进行更改
配置如下:
更改filebeat配置文件:
vim /etc/filebeat/filebeat.yml
#----------------------------- Logstash output -------------------------------- #注意,Logstashoutput配置段在配置文件中原来就存在,无需添加
#output.logstash: #由于需要把数据输出到redis,因此需要注释掉该选项
# The Logstash hosts
# hosts: ["192.168.32.154:5044"] #由于需要把数据输出到redis,因此需要注释掉该选项
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
#------------------------------- Redis output ---------------------------------- #redis配置端为新增配置段
output.redis: #启用该选项,去掉行首注释符,把数据输出到redis
# Boolean flag to enable or disable the output module.
enabled: true
# The list of Redis servers to connect to. If load balancing is enabled, the
# events are distributed to the servers in the list. If one server becomes
# unreachable, the events are distributed to the reachable servers only.
hosts: ["192.168.32.154:6379"] #启用该选项,去掉行首注释符,指定redis主机的ip和端口,如果有多个redis主机,可以是一个列表
# The Redis port to use if hosts does not contain a port number. The default
# is 6379.
port: 6379 #启用该选项,去掉行首注释符,指定监听端口
# The name of the Redis list or channel the events are published to. The
# default is filebeat.
key: filebeat #启用该选项,去掉行首注释符,指定key的类型
# The password to authenticate with. The default is no authentication.
password: magedu.com #启用该选项,去掉行首注释符,指定连接redis的密码
# The Redis database number where the events are published. The default is 0.
db: 0 #启用该选项,去掉行首注释符,指定redis数据库
# The Redis data type to use for publishing events. If the data type is list,
# the Redis RPUSH command is used. If the data type is channel, the Redis
# PUBLISH command is used. The default value is list.
datatype: list #启用该选项,去掉行首注释符,指定key对应的值为一个列表
注意:配置每个选项时冒号后面要有空格,如port: 6379
启动filebeat服务
systemctl start filebeat
查看进程是否启动
ps aux|grep filebeat
在客户端使用循环命令继续访问httpd服务生成日志
while true;do curl -H "X-Forwarded-For:$[$RANDOM%223+1].$[$RANDOM%225].$[$RANDOM%225].$[$RANDOM%225]" http://192.168.32.154/test$[$RANDOM%30+1].html;sleep 0.5;done;
在本机连接到redis数据查看日志
redis-cli -a magedu.com
127.0.0.1:6379> KEYS * 查看键值
127.0.0.1:6379> LINDEX filebeat 0 查看filebeat索引为0的数据
127.0.0.1:6379> LLEN filebeat 查看存放日志条数由于redis中的数据要输出到logstash server上,因此在logstash server上需要配置新的输入插件:
更改logstash子配置文件:
cd /etc/logstash/conf.d
cp beats_els.conf redis-els.conf
vim redis-els.conf
[root@master conf.d]# vim redis-els.conf
input {
redis{
host => "192.168.32.154" #输出数据的主机
port => 6379 #输出数据的主机端口
password => "magedu.com" #连接redis的密码
db => 0 #指定第几个数据库
key => "filebeat" #获取数据的数据库的键
data_type => "list" #指定数据类型,如果数据类型为number,则后面指定的值不能加引号,如果数据类型为string,则后面指定的值需要加引号,
}
}
filter {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message","beat"]
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02
.magedu.com:9200","http://node03.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "httpd_access_logs"
}
}
进行语法测试
logstash -f redis-els.conf -t
查看redis中存储的日志数量
127.0.0.1:6379> LLEN filebeat
(integer) 2049
注意:一旦启用logstash,则redis中的日志条数会被读取走,因此redis中的日志条数也会逐渐减少直至为0,如下所示:
127.0.0.1:6379> LLEN filebeat
(integer) 0
在192.168.32.152主机查询日志结果信息
curl http://node01:9200/logstash-*/_search?q=response:404 | jq . 注意:此时redis和logstash server仍然存在单点问题,可以把redis作为集群,logstash也可以作为多个或者使用keeplived实现高可用
必要的情况下,需要配置logstash server多个输入插件,从多个不同位置获取数据,即便是从同一个redis server获取日志,redis内容也应该使用不同的键保存不同的信息。比如说,tomcat上搜集的访问日志,可以输出到redis中,保存在0号数据库中,使用access作为键,搜集的catalina日志,使用catalina作为键,保存在两个不同的队列。
在logstash端,通过两个不同的键(这里要有两个redis)加载数据,对这两种不同的日志调用不同的过滤器插件进行分别过滤,调用elasticsearch的同一个输出插件,但有可能将数据输出到不同的索引中去
- 在logstash配置文件中使用if进行条件判断
- 引用json格式的文档
引用顶级字段
if [response]
引用三级字段
if [geoip][location][lon]
其中geoip为顶级字段,location为二级字段,lon为三级字段 - 引用字段并插入日志文件中,更改filebeat配置文件
示例:
更改filebeat配置文件:
vim /etc/filebeat/filebeat.yml
#=========================== Filebeat prospectors =============================
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/httpd/access_log #定义访问日志路径
fields: #定义引用日志字段
logtype: access #该信息会自动被当做一个字段插入到filebeat日志当中,发送给redis,最后进入logstash中
#- c:\programdata\elasticsearch\logs\*
#================================ Logging =====================================
logging.level: debug #开启调试模式,便于排错
重启filebeat服务
systemctl restart filebeat
查看filebeat进程是否启用
ps aux
登录redis数据库,查看日志信息
redis-cli -a magedu.com
127.0.0.1:6379> LLEN filebeat #查看日志条数
(integer) 300
127.0.0.1:6379> LINDEX filebeat 300 #查看最后一条日志信息,其中包括fields字段
"{\"@timestamp\":\"2019-03-19T07:45:41.132Z\",\"beat\":{\"hostname\":\"master.magedu.com\",\"name\":\"master.magedu.com\",\"version\":\"5.6.8\"},\"fields\":{\"logtype\":\"access\"},\"input_type\":\"log\",\"message\":\"166.94.124.0 - - [19/Mar/2019:15:45:40 +0800] \\\"GET /test6.html HTTP/1.1\\\" 200 7 \\\"-\\\" \\\"curl/7.29.0\\\"\",\"offset\":663630,\"source\":\"/var/log/httpd/access_log\",\"type\":\"log\"}"在配置文件中增加错误日志并插入字段:
配置文件如下:
vim /etc/filebeat/filebeat.yml
#=========================== Filebeat prospectors =============================
- input_type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/httpd/access_log #定义访问日志路径
fields: #定义引用日志字段
logtype: access #该信息会自动被当做一个字段插入到filebeat日志当中,发送给redis,最后进入logstash中
#- c:\programdata\elasticsearch\logs\*
- paths:
- /var/log/httpd/error_log #定义错误日志路径
fields: #定义引用错误日志字段
logtype: errors #该信息会自动被当做一个字段插入到filebeat日志当中,发送给redis,最后进入logstash中
登录redis查看日志信息
redis-cli -a magedu.com
127.0.0.1:6379> LLEN filebeat
(integer) 840
127.0.0.1:6379> LINDEX filebeat 840在logstash server主机上根据不同的字段对日志信息进行过滤
更改logstash子配置文件
cd /etc/logstash/conf.d/
cp redis-els.conf redis-condition-els.conf
vim redis-condition-els.conf
input {
redis{
host => "192.168.32.154"
port => 6379
password => "magedu.com"
db => 0
key => "filebeat"
data_type => "list"
}
}
filter {
if [fields][logtype] == "access" { #使用条件判断只对access日志进行过滤,其他类型的日志不做处理。这里fields为顶级字段,log_type为fields下的二级字段
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}" }
remove_field => ["message","beat"]
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
}
output {
if [fields][logtype] == "access" { #使用条件判断,如果日志字段类型为access,就执行以下操作
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200","http://node03.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "httpd_access_logs"
}
} else { #否则(日志字段类型不是access),就执行以下操作
elasticsearch {
hosts => ["http://node01.magedu.com:9200/","http://node02.magedu.com:9200","http://node03.magedu.com:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "httpd_error_logs"
}
}
}
更改启动logstash的方式
把/etc/logstash/conf.d目录下除了redis-condition-els.conf文件之外的其他文件移动到/root/logstash.conf目录下
ls /etc/logstash/conf.d/
redis-condition-els.conf
启动logstash服务
systemctl start logstash
注意:由于/etc/logstash/conf.d目录下只有一个配置文件,因此可以使用这种方式启动logstash,而且这才是logstash正常的启动方式
在192.168.32.153主机查看返回结果
curl http://node01:9200/logstash-*/_search?q=response:404 | jq . 5.3 Kibana配置介绍
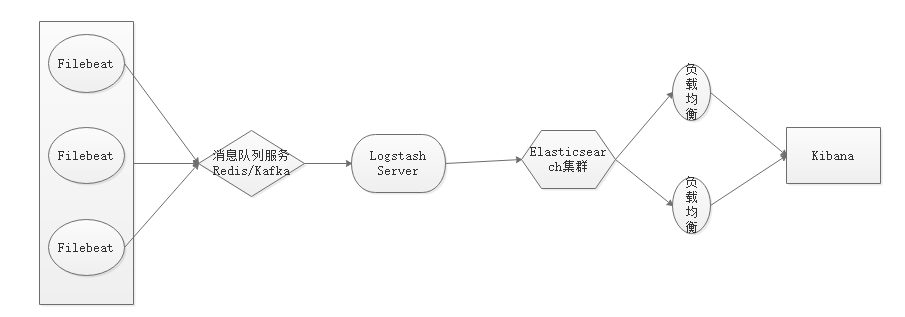
-
Kibana图形界面展示
这里为了便于实验,仍然在192.168.32.154主机上安装kibana -
架构图如下所示:
-
下载kibana软件包并安装
rpm -ivh kibana-5.6.8-x86_64.rpm -
配置文件
/etc/kibana/kibana.yml 主配置文件
配置kibana:
更改kibana配置文件
vim /etc/kibana/kibana.yml
server.port: 5601 #默认监听5601,如果想要更改为80端口,要确认本机80端口没有被使用,还要确定普通用户能够打开小于1024的端口。如果有必要可以在本地安装nginx进行反代,如果一个kibana压力过大,可以配置多台组成集群,使用nginx进行负载均衡
server.host: "0.0.0.0" #定义服务器监听的ip地址,这里定义监听本机所有可用地址
#server.basePath: "" #定义是否可以同子url进行输出,这里不启用该选项
#server.maxPayloadBytes: 1048576 #服务端发送和输出时最大的负载,这里不启用该选项
server.name: "master.magedu.com" #kibana服务器的主机名
elasticsearch.url: "http://192.168.32.151:9200" #指定elasticsearch的主机地址和端口。
#注意:为了防止出现elasticsearch单点,可以使用keeplived对其做高可用或者使用nginx反代并对elasticsearch做健康检测
elasticsearch.preserveHost: true #在elasticsearch访问时是否保留原来主机头,true表示保留
kibana.index: ".kibana" #是否保留kibana自身的索引
#elasticsearch.username: "user" #elasticsearch启用认证时的用户名,这里不启用该选项
#elasticsearch.password: "pass" #elasticsearch启用认证时的密码,这里不启用该选项-
启动kibana并查看kibana端口是否启动
systemctl start kibana -
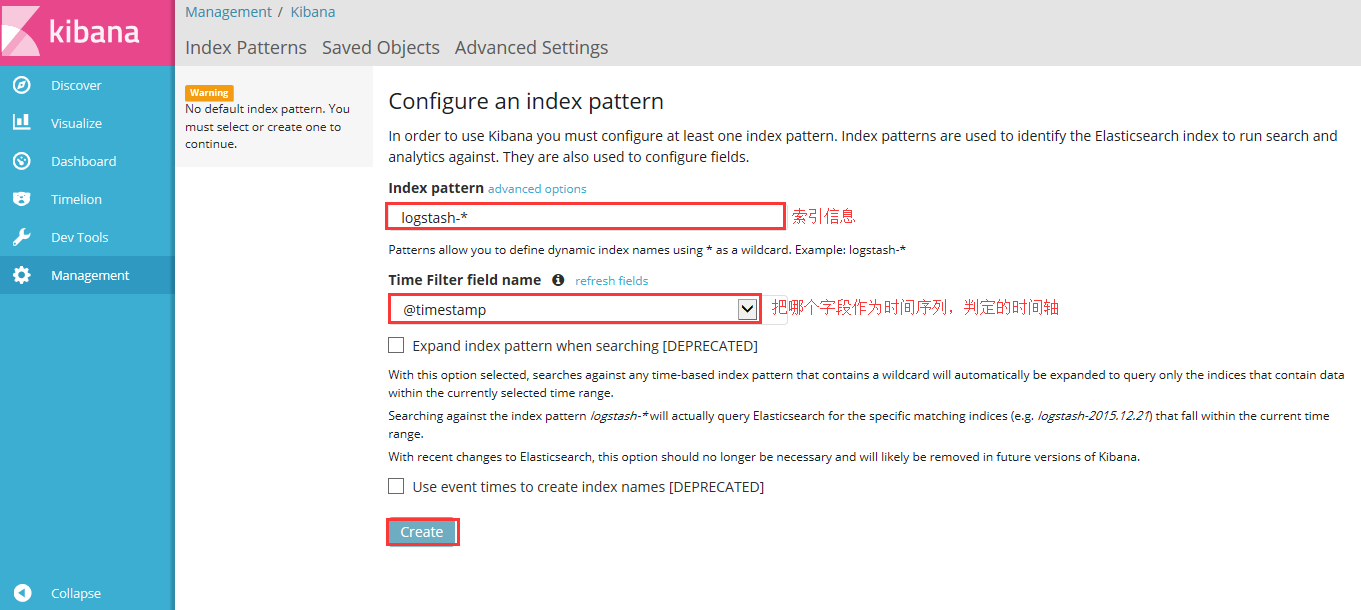
访问kibana
192.168.32.154:5601
访问界面如下所示:
加载字段:
-
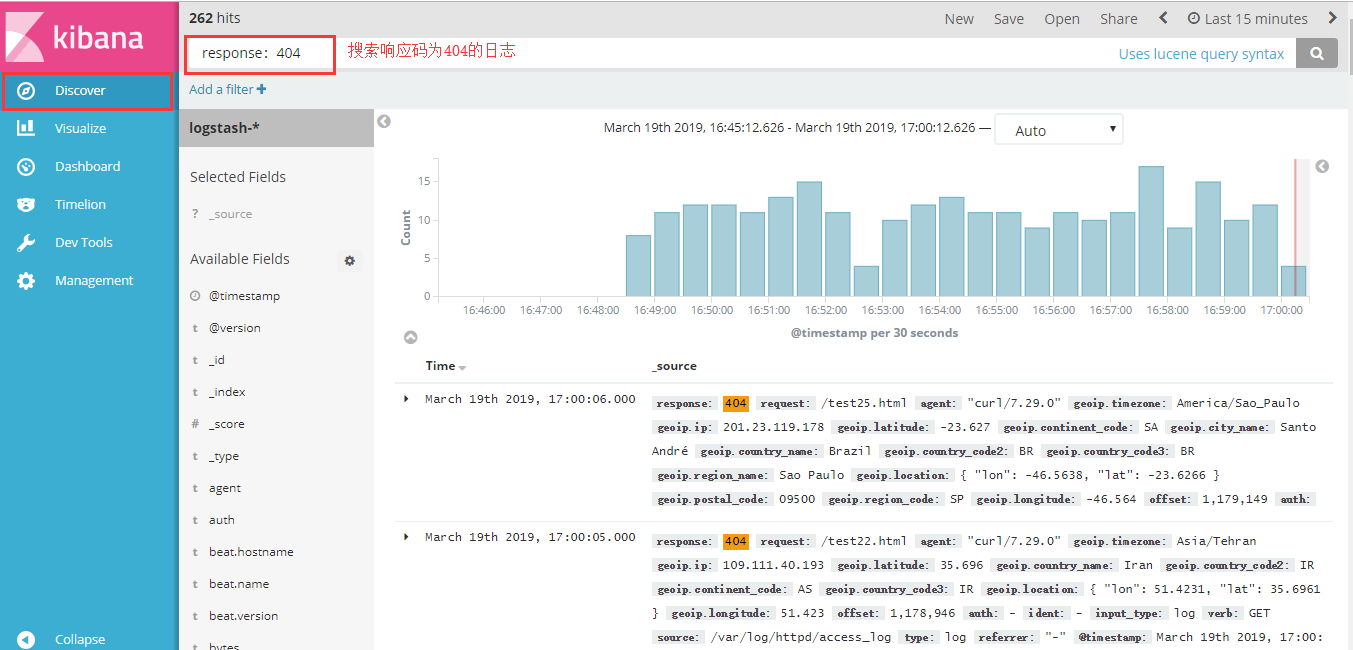
日志搜索
response:404 单项查询
response:404 OR response:200 逻辑或查询
response:[200 TO 404] 范围查询
agent:curl
对字符串搜索要使用{}定义 -
Kibana Web界面介绍
Discover日志搜索界面
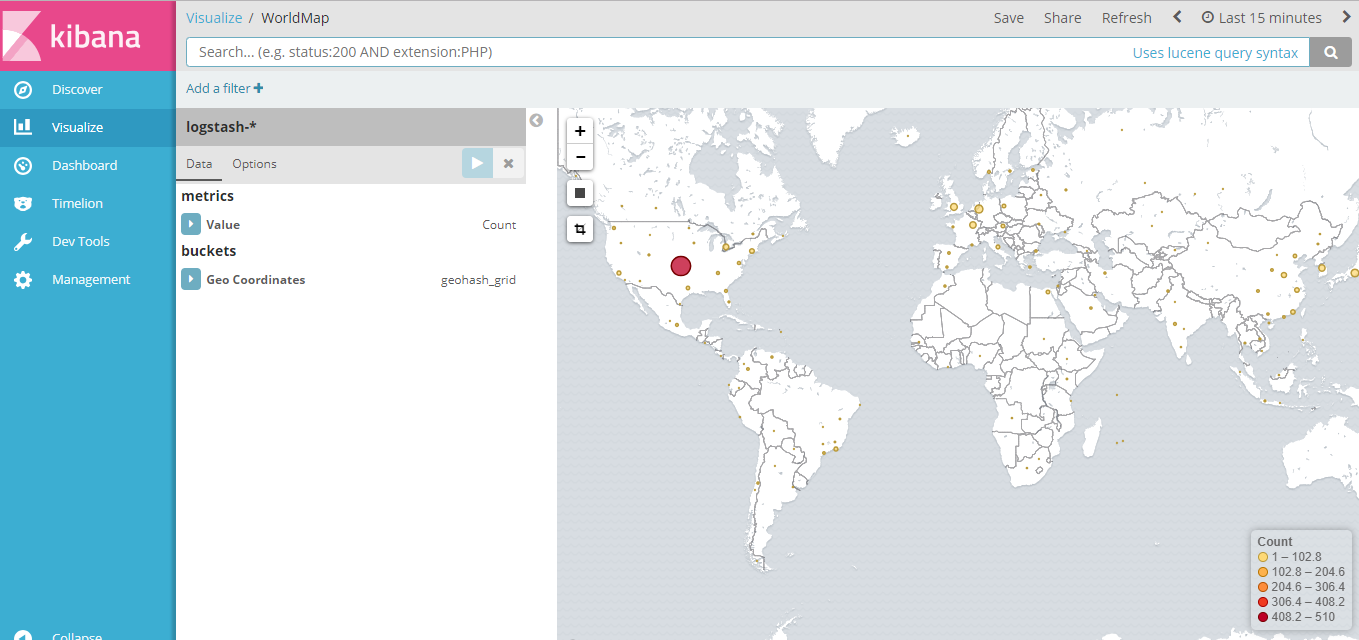
Visualize图形展示
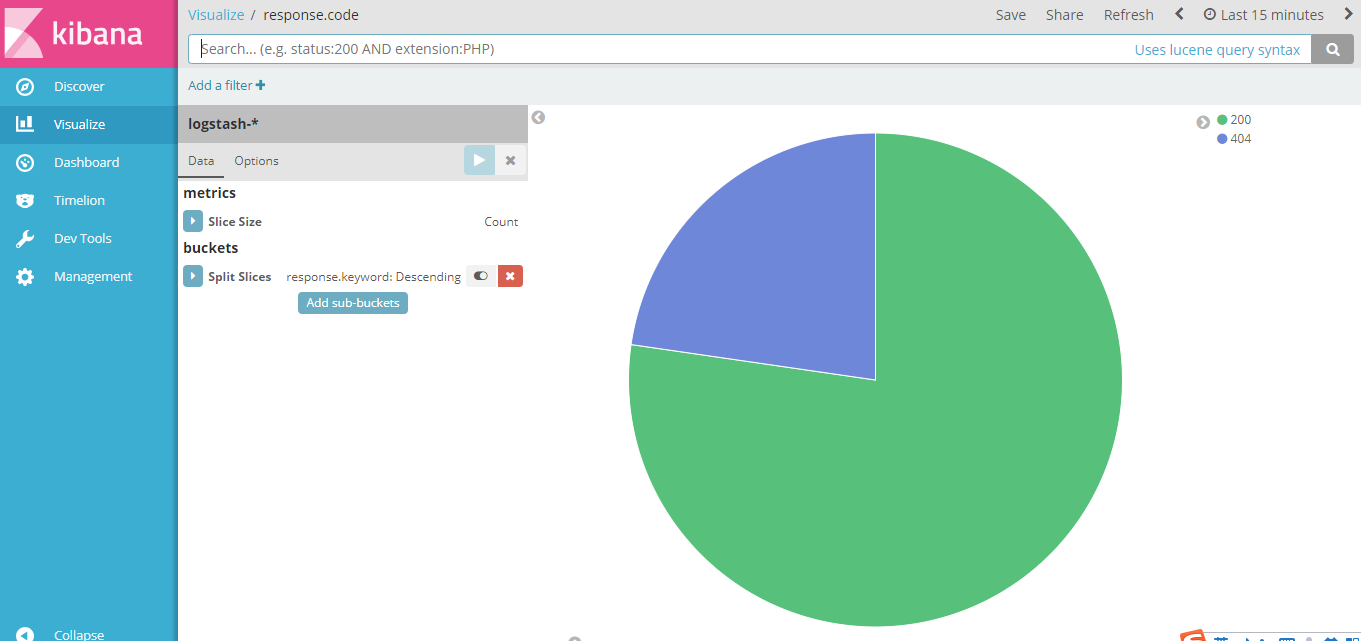
Dashboard ip地址地理位置显示
Dashboard多图形展示
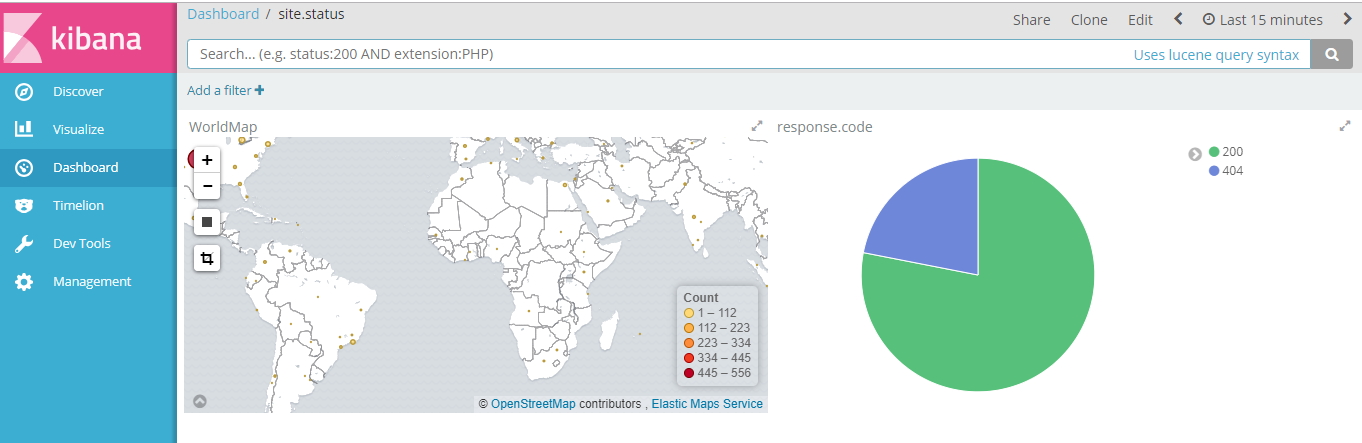
注意:当前对kibana的访问时开放的,安全起见需要做认证,可以使用nginx进行反代,同时启动basic认证

文章评论