
本章概述
- 通过手动调整pod
- 动态伸缩控制器HPA
前言
pod伸缩策略:
根据当前pod的负载,动态调整 pod副本数量,业务高峰期自动扩容pod的副本数以尽快响应pod的请求,业务低峰期对pod进行缩容,实现降本增效的目的。
pod级别的扩容缩容一般是根据pod资源(CPU、内存)的使用情况进行扩容缩容。比如:设置扩容阈值为80%,缩容阈值为40%,当pod资源资源使用率达到80%,就对当前pod进行自动扩容,当pod资源使用率低于等于40%,就对当前pod进行缩容。
另外,还可以设置pod扩容数量的最大值和缩容的最小值。比如设置扩容数量阈值为30,缩容数量阈值为5台,那么扩容时最多只能扩容30个pod,缩容最少要保留5个pod。
HPA控制器通过K8S集群接口获取集群中pod资源使用情况,当资源使用达到阈值时,会告诉资源控制器对pod进行扩缩容。
公有云支持node级别的弹性伸缩。
10.1 通过手动调整pod
通过手动调整pod的方式,在很多场景并不适用,而且效率较低,这里只做了解
10.1.1 通过dashboard调整
登录dashboard控制台,点击Deployment,点击右侧控制后面的操作项,选择对provider容器进行缩放
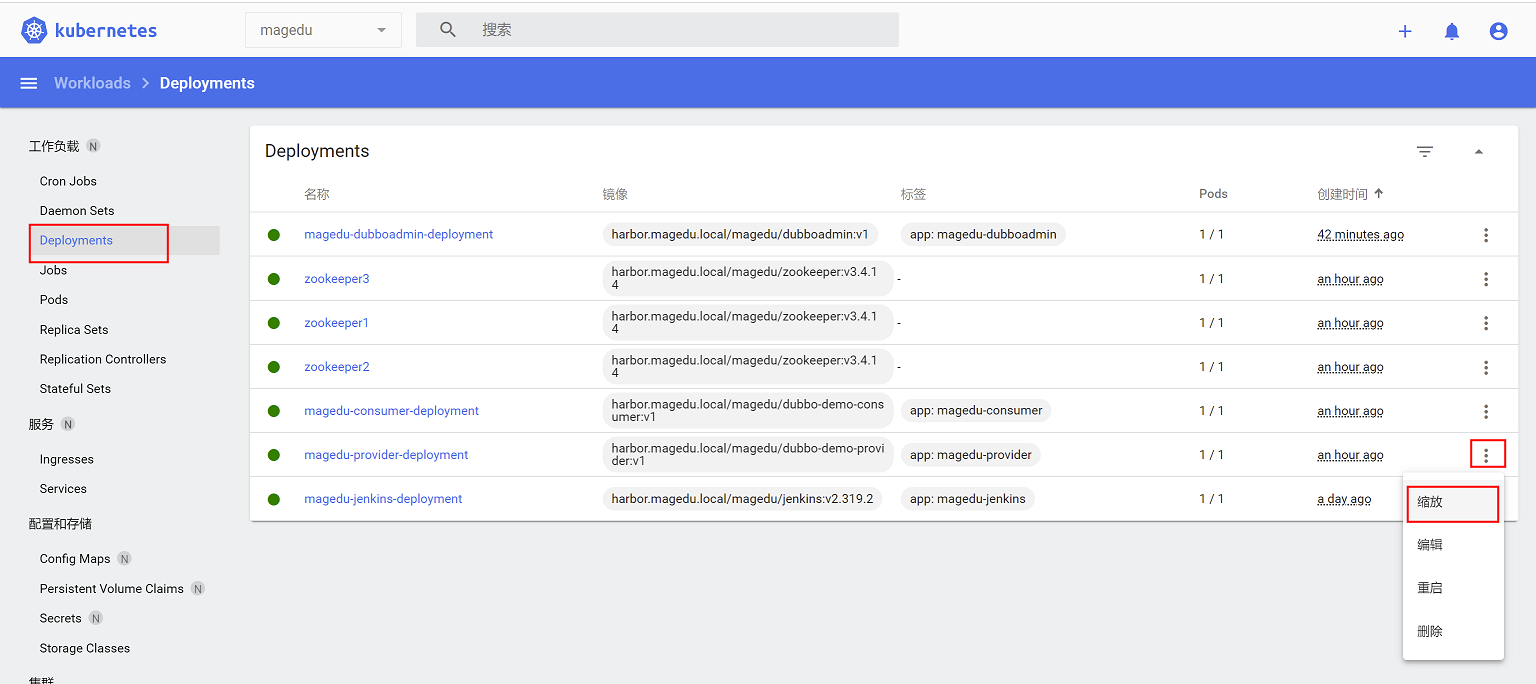
调整缩放策略(这里由1个调整为3个)

查看pod,会立马新建2个pod
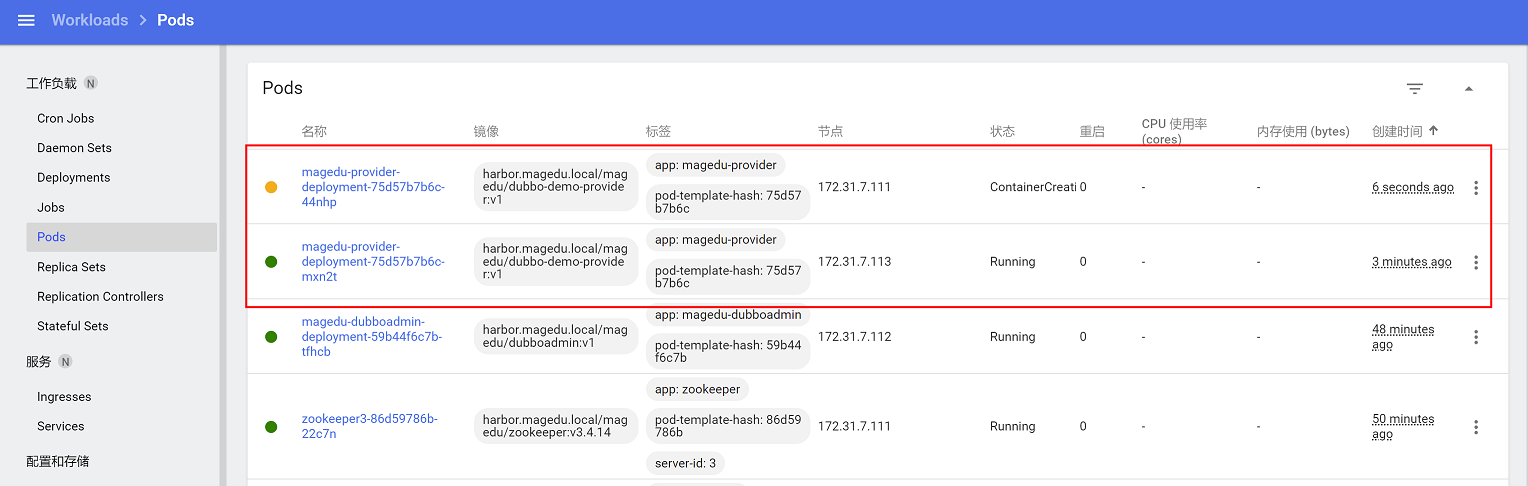
10.1.2 通过命令行调整
使用kubectl scale命令实现
命令格式:
kubectl scale --replicas=2 deployment/magedu-provider-deployment -n magedu
参数说明:
--replicas=2 #指定副本数
deployment/magedu-provider-deployment #斜线“/”前为资源类型,可以是replicaset、deployment、statefulset三种控制器,这里为deployment;斜线“/”后是控制器名称
-n magedu #指定namespace查看provider控制器(READY由3个变为2个)
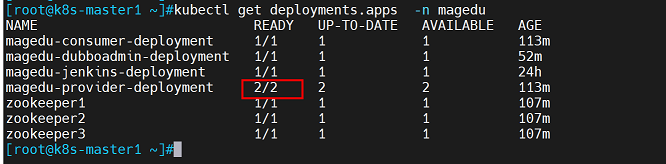
查看provider容器状态(provider只有2个)
10.2 动态伸缩控制器HPA
水平pod自动缩放器(HPA):
基于pod 资源利用率横向调整pod副本数量。
垂直pod自动缩放器(VPA):
基于pod资源利用率,调整对单个pod的最大资源限制,不能与HPA同时使用。
集群伸缩(Cluster Autoscaler,CA)
基于集群中node 资源分配情况,动态伸缩node节点,从而保证有CPU和内存资源用于创建pod。
这里需要提到一个关键组件:metrices-server
10.2.1 HPA控制器简介
Horizontal Pod Autoscaling (HPA)控制器,根据预定义好的阈值及pod当前的资源利用率,自动控制在k8s集群中运行的pod数量(自动弹性水平自动伸缩)。
通过命令获取参数:kube-controller-manager --help
--horizontal-pod-autoscaler-sync-period # HPA控制器同步pod副本数的间隔周期,默认每隔15s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况。
--horizontal-pod-autoscaler-downscale-stabilization #缩容间隔周期,默认5分钟。
与之相对应的是扩容间隔周期,默认15s,但参数已经被删除,无法配置,当前版本扩容能很快实现。
--horizontal-pod-autoscaler-cpu-initialization-period #初始化延迟时间,在此时间内 pod的CPU 资源指标将不会生效,默认为5分钟。
--horizontal-pod-autoscaler-initial-readiness-delay #用于设置 pod 准备时间, 在此时间内的 pod 统统被认为未就绪及不采集数据,默认为30秒。如果设置该参数后,会结合--horizontal-pod-autoscaler-cpu-initialization-period参数(初始化延迟时间(5分钟)),即5分30秒之内不会采集数据。
--horizontal-pod-autoscaler-tolerance #HPA控制器能容忍的数据差异(浮点数,默认为0.1),即新的指标要与当前的阈值差异在0.1或以上,即大于1+0.1=1.1,或小于1-0.1=0.9,比如阈值为CPU利用率50%,当前资源使用率为80%,那么80/50=1.6 > 1.1则会触发扩容,反之会缩容。即触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9,把N个pod的数据相加后根据pod的数量计算出平均数除以阈值,大于1.1就扩容,小于0.9就缩容。
即用当前所有pod资源使用率的平均值除以设置的阈值,得到的值大于1.1就扩容,小于0.9就缩容。假设共有2个pod,CPU使用率为85%和95%,则CPU使用率的平均值为(85+95)/2=90%,而设置的阈值为50%,90/50=1.8,该值大于1.1就会扩容;假设所有pod资源使用率平均值为20%,阈值为50%,20/50=0.4.该值小于0.9,就会缩容。
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) #ceil是一个向上取整的目的pod整数(不足1个按照1个计算)指标数据采集需要部署metrics-server,即HPA使用metrics-server作为数据源。
github链接:https://github.com/kubernetes-sigs/metrics-server
在k8s 1.1引入HPA控制器,早期使用Heapster组件采集pod指标数据,在k8s 1.11版本开始使用Metrices Server完成数据采集,然后将采集到的数据通过API(Aggregated API,汇总API),例如metrics.k8s.io、custom.metrics.k8s.io、external.metrics.k8s.io,然后再把数据提供给HPA控制器进行查询,以实现基于某个资源利用率对pod进行扩缩容的目的。
pod伸缩流程:
(1)HPA每隔15s查询一次Metrices Serve数据
(2)如果pod使用情况触发阈值,HAP就会进行调整,否则将会保持不变
(3)HPA控制器根据计算公式计算出需要进行伸缩的值,然后告知关联的控制器进行伸缩调整10.2.2 Metrics Server
10.2.2.1 metrics server介绍
Metrics Server 是 Kubernetes 内置的容器资源指标来源。
Metrics Server 从node节点上的 Kubelet 收集资源指标,并通过Metrics API在 Kubernetes apiserver 中公开指标数据,以供Horizontal Pod Autoscaler和Vertical Pod Autoscaler使用,也可以通过访问kubectl top node/pod 查看指标数据。
在未部署metrics server时使用kubectl top node/pod命令会报错:

结构图如下:
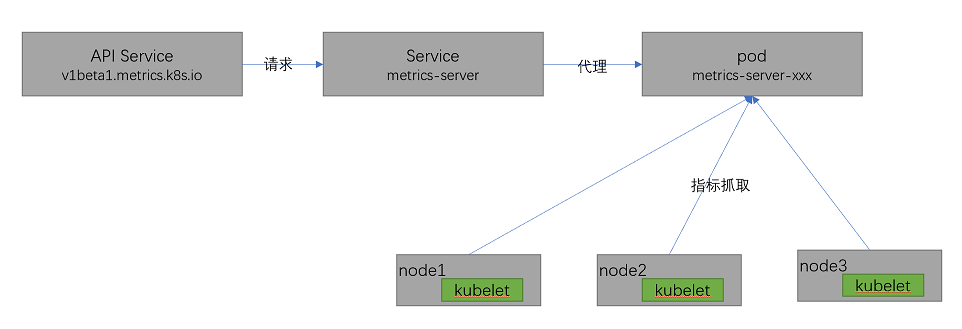
访问流程如下:
1、metrics-server通过kebelet获取pod数据
2、API Service向metrics-server的service请求数据
3、metrics-server service将请求转发给metrics-server pod
4、metrics-server将抓取的数据返回
metrics-server版本兼容性:

备注:1.19+ 表示兼容1.19以上的版本。只兼容向上版本,不兼容向下版本
10.2.2.2 metrics server部署
通过github获取部署metrics server的yaml文件
yaml文件链接:https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
但是该文件中使用的镜像所在仓库是google镜像仓库,无法下载,需要科学上网获取镜像,或者更改为docker官方镜像,更改方式如下:
1、下载docker官网metrics-server镜像并上传到harbor镜像仓库
docker pull bitnami/metrics-server:0.6.1
docker tag bitnami/metrics-server:0.6.1 harbor.magedu.local/magedu/metrics-server:0.6.1
docker push harbor.magedu.local/magedu/metrics-server:0.6.12、下载metrics-server的yaml文件并更改yaml文件中镜像
cd /root/yaml/20220515/
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
vim components.yaml #这里只贴出修改部分
image: harbor.magedu.local/magedu/metrics-server:0.6.1
修改yaml文件名称:
mv components.yaml metrics-server.yaml3、部署metircs-server
kubectl apply -f metrics-server.yaml
查看metrics-server
kubectl get pod -n kube-system -o wide

4、验证
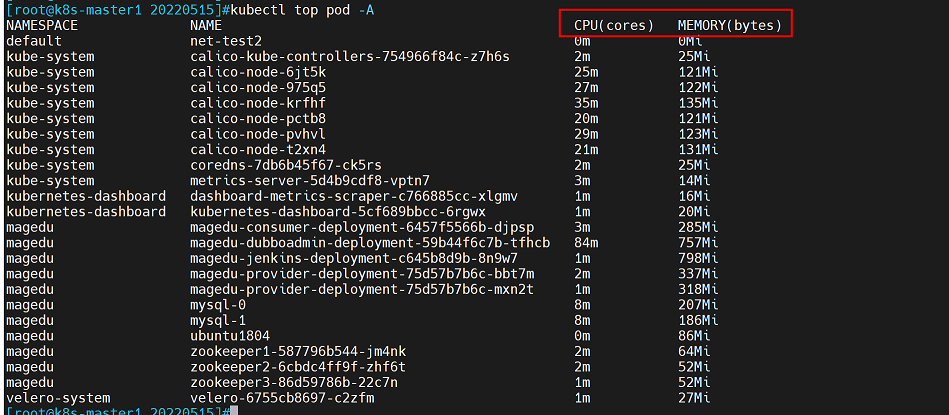
执行命令查看资源使用率
kubectl top node #查看node资源使用率

kubectl top pod #查看pod资源使用率
注意:在使用HPA控制器时一定要在yaml文件中加上资源限制,如果不加,HPA控制器无法采集到pod数据
10.2.3 HPA控制器自动伸缩效果演示
10.2.3.1 部署压测pod
为了便于后续演示HPA控制器的自动伸缩效果,部署测试用的pod
yaml文件:
vim tomcat-app1.yaml
kind: Deployment
#apiVersion: extensions/v1beta1
apiVersion: apps/v1
metadata:
labels:
app: magedu-tomcat-app1-deployment-label
name: magedu-tomcat-app1-deployment
namespace: magedu
spec:
replicas: 2
selector:
matchLabels:
app: magedu-tomcat-app1-selector
template:
metadata:
labels:
app: magedu-tomcat-app1-selector
spec:
containers:
- name: magedu-tomcat-app1-container
#image: harbor.magedu.local/magedu/tomcat-app1:v7
#image: tomcat:7.0.93-alpine
image: lorel/docker-stress-ng #指定压测镜像
args: ["--vm", "2", "--vm-bytes", "256M"] #指定两个进程占用2核CPU,每个进程占用256M内存,共占用2*256M内存。由于tomcat资源限制只能使用1核CPU和512M内存,一旦部署该pod,资源会被立即占完。
##command: ["/apps/tomcat/bin/run_tomcat.sh"]
imagePullPolicy: IfNotPresent
##imagePullPolicy: Always
ports:
- containerPort: 8080
protocol: TCP
name: http
env:
- name: "password"
value: "123456"
- name: "age"
value: "18"
resources:
limits: #资源限制,只能使用1核CPU,512M内存
cpu: 1
memory: "512Mi"
requests:
cpu: 500m
memory: "512Mi"
---
kind: Service
apiVersion: v1
metadata:
labels:
app: magedu-tomcat-app1-service-label
name: magedu-tomcat-app1-service
namespace: magedu
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: 8080
nodePort: 40003
selector:
app: magedu-tomcat-app1-selector注意:通过压测镜像,指定占用的进程和内存,使得该pod一旦部署,会占用2核CPU,2*256M(即512M)内存。但由于tomcat资源限制只能使用1核CPU和512M内存,因此一旦部署该pod,资源会被立即占完。
部署pod
kubectl apply -f tomcat-app1.yaml
查看pod
查看pod资源使用率,资源使用率较高
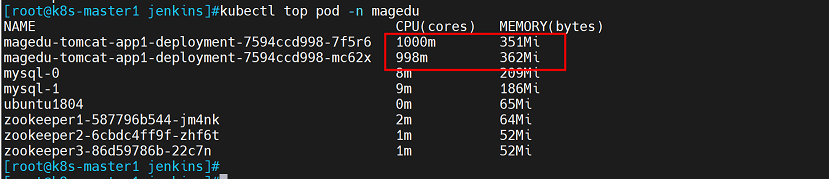
但是由于没有配置HPA控制器以及伸缩策略,无法进行自动伸缩。
10.2.3.2 创建HPA控制器
创建方式有两种:1、命令行手动创建 2、通过yaml文件创建
推荐使用yaml文件创建HAP控制器
1、命令行方式:
kubectl autoscale deployment --min=2 --max=5 --cpu-percent=80 #cpu利用率高于80%就扩容,最多由5个副本,低于80%就缩容,最少由2个副本
命令格式说明:
deployment #指定控制器类型
--min #指定最小副本数
--max #指定最大副本数
--cpu-percent #指定资源扩缩容的阈值2、通过yaml文件创建HPA控制器
vim hpa.yaml
#apiVersion: autoscaling/v2beta1
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
namespace: magedu #hpa控制器必须和业务容器在同一个namespce
name: magedu-tomcat-app1-podautoscaler
labels:
app: magedu-tomcat-app1
version: v2beta1
spec:
scaleTargetRef: #定义水平伸缩的目标对象,Deployment、ReplicationController/ReplicaSet
apiVersion: apps/v1 #指定控制器的版本
#apiVersion: extensions/v1beta1
kind: Deployment #目标对象类型为deployment
name: magedu-tomcat-app1-deployment
minReplicas: 3 #最小pod数
maxReplicas: 8 #最大pod数
targetCPUUtilizationPercentage: 60 #设置CPU使用率阈值为60%
#metrics:
#- type: Resource
# resource:
# name: cpu
# targetAverageUtilization: 60
#- type: Resource
# resource:
# name: memory创建hpa控制器
kubectl apply -f hpa.yaml
查看hpa控制器

注意:如果yaml文件中不配置资源限制,hpa控制器创建以后,显示如下:

10.2.3.3 验证HPA控制器自动伸缩功能
验证1:
hpa自动扩容功能
注意:由于配置的最小副本数为3,一旦创建hpa控制器,hpa控制器会自动添加一个pod副本(创建tomcat容器的yaml文件中设置副本数为2),满足hpa控制器的最小副本数

而此时HPA控制器已经获取到压测容器的CPU使用率为200%

根据计算公式可以得出:
两个pod的CPU资源使用率为200%,则平均使用率为200%/2=100%
而设置的CPU阈值为60,平均使用率/阈值:100%/60%=1.6
1.6>1.1,因此会对tomcat容器进行扩容。根据hpa yaml文件的配置,扩容最大值为8,缩容最小值为3,因此会扩容8个副本
查看tomcat容器副本数

查看hpa容器日志
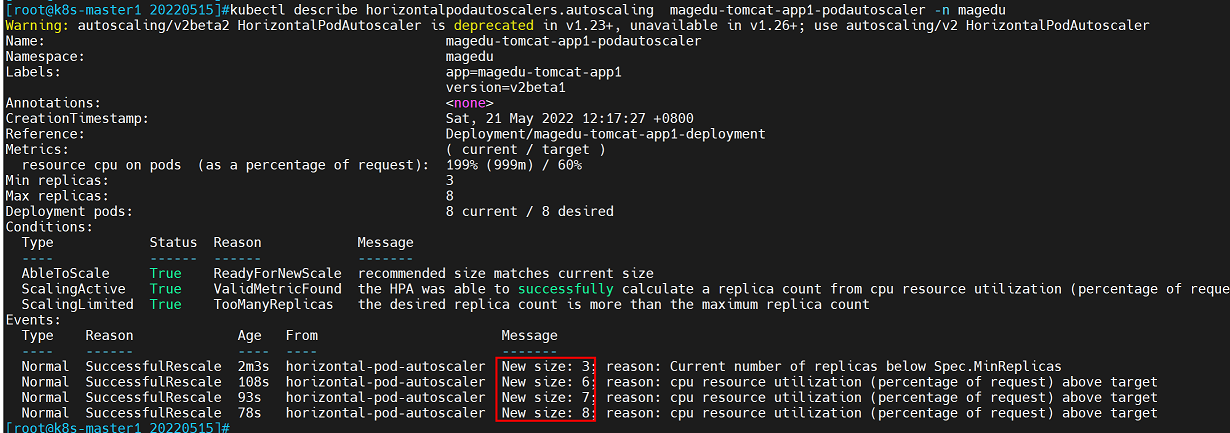
使用describe命令查看hpa控制,存在以下参数:
desired 最终期望处于READY状态的副本数
updated 当前完成更新的副本数
total 总计副本数
available 当前可用的副本数
unavailable 不可用副本数查看日志显示先创建3个副本,满足hpa最小副本数的要求,然后直接创建6个。这是因为:
根据计算公式可以得出:
3个容器,CPU全部占满,CPU使用率为300%,但实际cpu使用率可能会稍高一些,如302%
302/60=5.03
而取的值是一个向上取整的目的pod整数,不足1按1计算,需要扩的数量为6,因此直接从3个扩容为6个。
继续计算:得到值为600/60=10
而后最大可扩容的副本数为8,因此后续会继续创建第7第8个容器,直到达到hpa yaml设置的可扩容副本上限。注意:容器创建的时间间隔为15s,是容器扩容的默认间隔时间。
验证2:
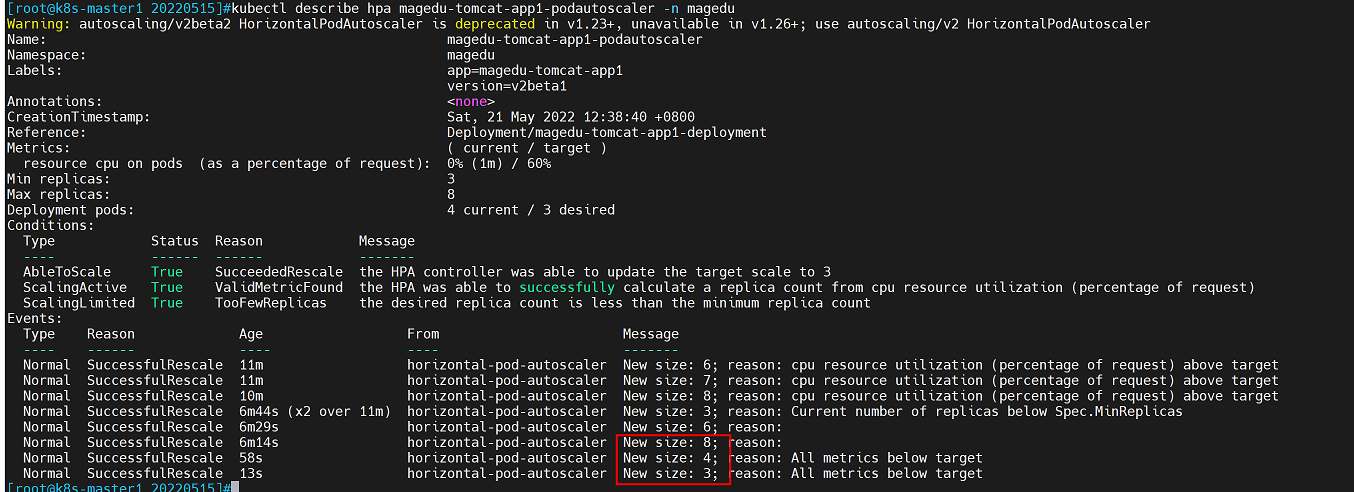
hpa自动缩容功能
将压测容器的yaml文件的镜像更改为正常的tomcat镜像
vim tomcat-app1.yaml
image: tomcat:7.0.93-alpine查看tomcat容器数量

查看hpa控制器日志,tomcat容器自动缩容为3个(yaml文件设置的最小副本数),缩容需要等待5分钟

文章评论